

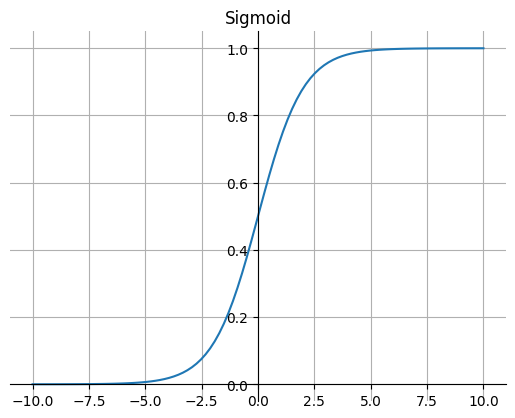
1. Sigmoid
Sigmoid 函数的图像看起来像一个 S 形曲线。
公式:

特点:
Sigmoid 函数的输出范围是 0 到 1。由于输出值在 0 到 1,所以它可以对每个神经元的输出进行了归一化。
因为Sigmoid 函数的输出范围是 0 到 1,所以可以用于将预测概率作为输出的模型。
梯度平滑,避免跳跃的输出值。
容易梯度消失。
函数输出不是以 0 为中心的,这会降低权重更新的效率。
Sigmoid 函数是指数运算,计算机运行得较慢。
2. Tanh
Tanh 函数的图像看起来像一个有点扁的 S 形曲线。Tanh 是一个双曲正切函数。Tanh 函数和 Sigmoid 函数的曲线相对相似。但是它比 Sigmoid 函数更有一些优势。
公式:
 特点:
特点:
首先,当输入较大或较小时,输出几乎是平滑的并且梯度较小,这不利于权重更新。二者的区别在于输出间隔,Tanh 的输出间隔为 1,并且整个函数以 0 为中心,比 Sigmoid 函数更好。
在 Tanh 图中,负数信号输入,输出也是负数信号。
在一般的二元分类问题中,Tanh 函数用于隐藏层,而 Sigmoid 函数用于输出层,但这并不是固定的,需要根据特定问题进行调整。
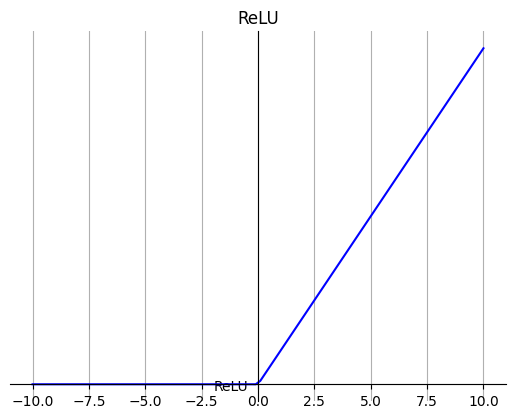
3. ReLU
ReLU 函数是深度学习中较为流行的一种激活函数。
公式:
 特点:
特点:
当输入为正时,不存在梯度饱和问题。
计算速度快。ReLU 函数中只存在线性关系,因此它的计算速度比 sigmoid 和 tanh 更快。
当输入为负时,ReLU 完全失效,在正向传播过程中,这不是问题。有些区域很敏感,有些则不敏感。但是在反向传播过程中,如果输入负数,则梯度将完全为零。
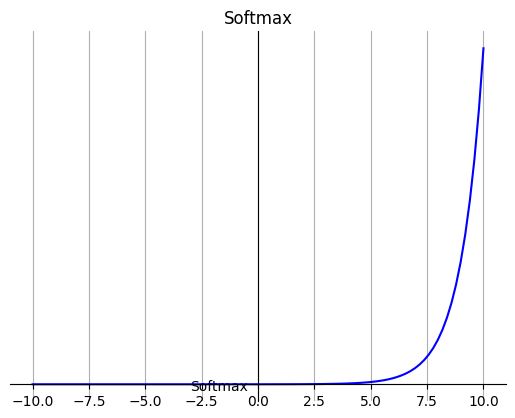
4. Softmax
公式:

特点:
在零点不可微。
负数信号输入的梯度为零,这意味着对于该区域的激活,权重不会在反向传播期间更新,因此会产生永不激活的死亡神经元。
Softmax 函数的分母结合了原始输出值的所有因子,这意味着 Softmax 函数获得的各种概率彼此相关,因此Softmax 是用于多类分类问题。
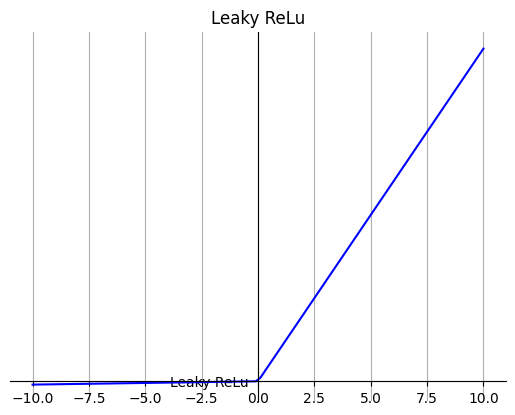
5. Leaky ReLU
它是一种专门设计用于解决 ReLU 梯度消失问题的激活函数。
公式:

特点:
Leaky ReLU 通过把 x 的非常小的线性分量给予负数信号来调整负值的零梯度问题。
leak 有助于扩大 ReLU 函数的范围,通常 a 的值为 0.01 左右。
注意: 从理论上讲,Leaky ReLU 具有 ReLU 的所有优点,而且 Dead ReLU 不会有任何问题,但在实际操作中,尚未完全证明 Leaky ReLU 总是比 ReLU 更好。
6. ELU
ELU 的提出也解决了 ReLU 的问题。与 ReLU 相比,ELU 有负值,这会使激活的平均值接近零。均值激活接近于零可以使学习更快,因为它们使梯度更接近自然梯度。
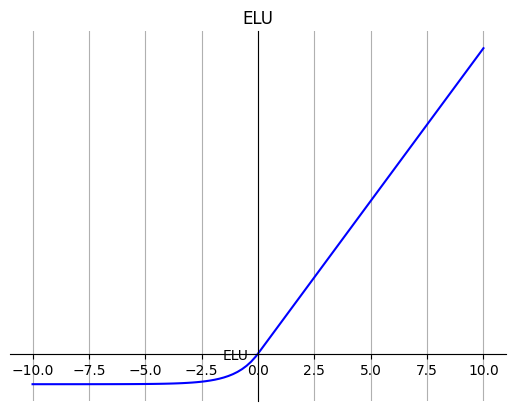
公式:

特点:
ELU 通过减少偏置偏移的影响,使正常梯度更接近于单位自然梯度,从而使均值向零加速学习。
ELU 在较小的输入下会饱和至负值,从而减少前向传播的变异和信息。
注意: 它的计算强度更高。与 Leaky ReLU 类似,尽管理论上比 ReLU 要好,但目前在实践中没有充分的证据表明 ELU 总是比 ReLU 好。
7. PReLU
PReLU 也是 ReLU 的改进版本。
公式:
 若α \alphaα是可学习的参数,则 f ( x ) f(x)f(x)变为 PReLU。
若α \alphaα是可学习的参数,则 f ( x ) f(x)f(x)变为 PReLU。
特点:
与 ELU 相比,PReLU 在负值域是线性运算。尽管斜率很小,但不会趋于 0。
8. Swish
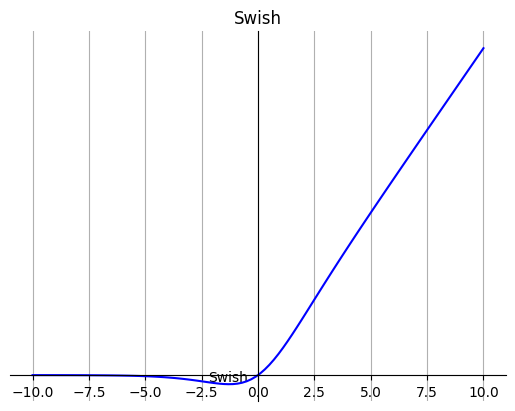
Swish 的设计受到了 LSTM 和高速网络中 gating 的 sigmoid 函数使用的启发。我们使用相同的 gating 值来简化 gating 机制,这称为 self-gating。
self-gating 的优点在于它只需要简单的标量输入,而普通的 gating 则需要多个标量输入。这使得诸如 Swish 之类的 self-gated 激活函数能够轻松替换以单个标量为输入的激活函数(例如 ReLU),而无需更改隐藏容量或参数数量。
公式:
 特点:
特点:
无界性有助于防止慢速训练期间,梯度逐渐接近 0 并导致饱和;(同时,有界性也是有优势的,因为有界激活函数可以具有很强的正则化,并且较大的负输入问题也能解决)。
导数恒大于零。
平滑度在优化和泛化中起了重要作用。
9. Squareplus
Squareplus是Softplus优化版本,Squareplus由超参数b>0定义,它决定了x=0附近弯曲区域的大小。
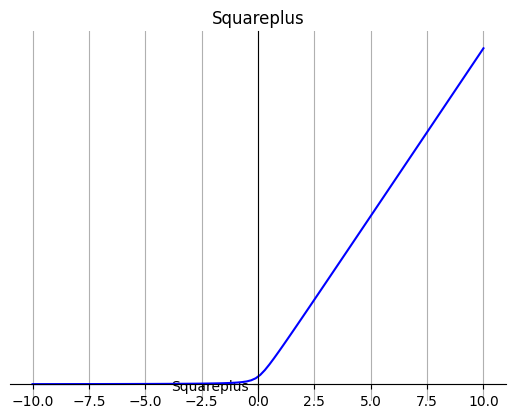
公式:
 特点:
特点:
它的输出是非负的。
它是ReLU的一个上界函数,会随着|x|的增长而接近ReLU。
它是连续的。
Squareplus只使用代数运算进行计算,这使得它非常适合计算资源或指令集有限的情况。此外,当x较大时,Squareplus无需特别考虑确保数值稳定性。
10. SMU
该函数是在已知激活函数Leaky ReLU近似的基础上,提出了一种新的激活函数,称之为Smooth Maximum Unit(SMU)。用SMU替换ReLU,ShuffleNet V2模型在CIFAR100数据集上得到了6.22%的提升。
参考:https://github.com/iFe1er/SMU_pytorch
各激活函数代码实现及绘图工具类代码
import matplotlib.pyplot as plt
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def tanh(x):
return 2 / (1 + np.exp(-2*x)) - 1
def relu(x):
return np.maximum(0, x)
def softmax(x):
x = np.exp(x) / np.sum(np.exp(x))
return x
def leaky_relu(x,a=0.01):
return np.maximum(a*x, x)
def elu(x,alpha=1):
a = x[x>0]
b = alpha*(np.exp(x[x<0])-1)
result=np.concatenate((b,a),axis=0)
return result
def swish(x):
return sigmoid(x) * x
def Squareplus(x, b=0.2):
x = 0.5 * (x + np.sqrt(x**2+b))
return x
def showImg(title,x,lines):
fig, ax = plt.subplots()
for line in lines:
ax.plot(x, line[0],line[1],line[2])
# ax.legend() # 设置图例
# 画轴
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
ax.spines['bottom'].set_position(('data', 0))
ax.spines['left'].set_position(('axes', 0.5))
plt.grid() # 设置方格
plt.title(title)
plt.show()
x = np.linspace(-10, 10, 100)
lines = np.array([[sigmoid(x),'b','Sigmoid']],dtype=object)
showImg("Sigmoid",np.linspace(-10, 10, 100),lines)
lines = np.array([[sigmoid(x),'b','Sigmoid']],dtype=object)
lines = np.vstack((lines_st,[[tanh(x), '-r', 'Tanh']]))
showImg("Tanh and Sigmoid",np.linspace(-10, 10, 100),lines)
lines = np.array([[relu(x),'b','ReLU']],dtype=object)
showImg("ReLU",np.linspace(-10, 10, 100),lines)
lines = np.array([[softmax(x),'b','Softmax']],dtype=object)
showImg("Softmax",np.linspace(-10, 10, 100),lines)
lines = np.array([[leaky_relu(x),'b','Leaky ReLu']],dtype=object)
showImg("Leaky ReLu",np.linspace(-10, 10, 100),lines)
lines = np.array([[elu(x),'b','ELU']],dtype=object)
showImg("ELU",np.linspace(-10, 10, 100),lines)
lines = np.array([[swish(x),'b','Swish']],dtype=object)
showImg("Swish",np.linspace(-10, 10, 100),lines)
lines = np.array([[Squareplus(x),'b','Squareplus']],dtype=object)
showImg("Squareplus",np.linspace(-10, 10, 100),lines)
import matplotlib.pyplot as plt
import numpy as np
class ActivateFunc():
def __init__(self, x, b=None, lamb=None, alpha=None, a=None):
super(ActivateFunc, self).__init__()
self.x = x
self.b = b
self.lamb = lamb
self.alpha = alpha
self.a = a
def Sigmoid(self):
y = np.exp(self.x) / (np.exp(self.x) + 1)
y_grad = y*(1-y)
return [y, y_grad]
def Tanh(self):
y = np.tanh(self.x)
y_grad = 1 - y * y
return [y, y_grad]
def softmax(self):
x = np.exp(self.x) / np.sum(np.exp(self.x))
return x
def Swish(self): #b是一个常数,指定b
y = self.x * (np.exp(self.b*self.x) / (np.exp(self.b*self.x) + 1))
y_grad = np.exp(self.b*self.x)/(1+np.exp(self.b*self.x)) + self.x * (self.b*np.exp(self.b*self.x) / ((1+np.exp(self.b*self.x))*(1+np.exp(self.b*self.x))))
return [y, y_grad]
def ELU(self): # alpha是个常数,指定alpha
y = np.where(self.x > 0, self.x, self.alpha * (np.exp(self.x) - 1))
y_grad = np.where(self.x > 0, 1, self.alpha * np.exp(self.x))
return [y, y_grad]
def SELU(self): # lamb大于1,指定lamb和alpha
y = np.where(self.x > 0, self.lamb * self.x, self.lamb * self.alpha * (np.exp(self.x) - 1))
y_grad = np.where(self.x > 0, self.lamb*1, self.lamb * self.alpha * np.exp(self.x))
return [y, y_grad]
def ReLU(self):
y = np.where(self.x < 0, 0, self.x)
y_grad = np.where(self.x < 0, 0, 1)
return [y, y_grad]
def PReLU(self): # a大于1,指定a
y = np.where(self.x < 0, self.x / self.a, self.x)
y_grad = np.where(self.x < 0, 1 / self.a, 1)
return [y, y_grad]
def LeakyReLU(self): # a大于1,指定a
y = np.where(self.x < 0, self.x / self.a, self.x)
y_grad = np.where(self.x < 0, 1 / self.a, 1)
return [y, y_grad]
def Mish(self):
f = 1 + np.exp(x)
y = self.x * ((f*f-1) / (f*f+1))
y_grad = (f*f-1) / (f*f+1) + self.x*(4*f*(f-1)) / ((f*f+1)*(f*f+1))
return [y, y_grad]
def ReLU6(self):
y = np.where(np.where(self.x < 0, 0, self.x) > 6, 6, np.where(self.x < 0, 0, self.x))
y_grad = np.where(self.x > 6, 0, np.where(self.x < 0, 0, 1))
return [y, y_grad]
def Hard_Swish(self):
f = self.x + 3
relu6 = np.where(np.where(f < 0, 0, f) > 6, 6, np.where(f < 0, 0, f))
relu6_grad = np.where(f > 6, 0, np.where(f < 0, 0, 1))
y = self.x * relu6 / 6
y_grad = relu6 / 6 + self.x * relu6_grad / 6
return [y, y_grad]
def Hard_Sigmoid(self):
f = (2 * self.x + 5) / 10
y = np.where(np.where(f > 1, 1, f) < 0, 0, np.where(f > 1, 1, f))
y_grad = np.where(f > 0, np.where(f >= 1, 0, 1 / 5), 0)
return [y, y_grad]
def PlotActiFunc(x, y, title):
plt.grid(which='minor', alpha=0.2)
plt.grid(which='major', alpha=0.5)
plt.plot(x, y)
plt.title(title)
plt.show()
def PlotMultiFunc(x, y):
plt.grid(which='minor', alpha=0.2)
plt.grid(which='major', alpha=0.5)
plt.plot(x, y)
if __name__ == '__main__':
x = np.arange(-10, 10, 0.01)
activateFunc = ActivateFunc(x)
activateFunc.b = 1
PlotActiFunc(x, activateFunc.Sigmoid()[0], title='Sigmoid')
PlotActiFunc(x, activateFunc.Tanh()[0], title='Tanh')
PlotActiFunc(x, activateFunc.Swish()[0], title='Swish')
PlotActiFunc(x, activateFunc.ReLU()[0], title='ReLU')
PlotActiFunc(x, activateFunc.Mish()[0], title='Mish')
PlotActiFunc(x, activateFunc.Mish()[1], title='Mish-grad')
PlotActiFunc(x, activateFunc.Swish()[1], title='Swish-grad')
plt.figure(1)
PlotMultiFunc(x, activateFunc.Mish()[1])
PlotMultiFunc(x, activateFunc.Swish()[1])
plt.legend(['Mish-grad', 'Swish-grad'])
plt.figure(2)
PlotMultiFunc(x, activateFunc.Swish()[0])
PlotMultiFunc(x, activateFunc.Mish()[0])
plt.legend(['Swish', 'Mish'])
plt.figure(3)
PlotMultiFunc(x, activateFunc.Swish()[0])
PlotMultiFunc(x, activateFunc.Hard_Swish()[0])
plt.legend(['Swish', 'Hard-Swish'])
plt.figure(4)
PlotMultiFunc(x, activateFunc.Sigmoid()[0])
PlotMultiFunc(x, activateFunc.Hard_Sigmoid()[0])
plt.legend(['Sigmoid', 'Hard-Sigmoid'])
plt.figure(5)
PlotMultiFunc(x, activateFunc.ReLU()[0])
PlotMultiFunc(x, activateFunc.ReLU6()[0])
plt.legend(['ReLU', 'ReLU6'])
plt.figure(6)
PlotMultiFunc(x, activateFunc.Swish()[1])
PlotMultiFunc(x, activateFunc.Hard_Swish()[1])
plt.legend(['Swish-grad', 'Hard-Swish-grad'])
plt.figure(7)
PlotMultiFunc(x, activateFunc.Sigmoid()[1])
PlotMultiFunc(x, activateFunc.Hard_Sigmoid()[1])
plt.legend(['Sigmoid-grad', 'Hard-Sigmoid-grad'])
plt.figure(8)
PlotMultiFunc(x, activateFunc.ReLU()[1])
PlotMultiFunc(x, activateFunc.ReLU6()[1])
plt.legend(['ReLU-grad', 'ReLU6-grad'])
plt.show()