

【BERT】详解BERT
一、为什么要提出BERT?
传统的RNN类模型,包括LSTM,GRU以及其他各种变体,最大的问题在于提取能力不足。在《Why Self-Attention? A Targeted Evaluation of Neural Machine Translation Architectures》中证明了RNN的长距离特征提取能力甚至不亚于Transformer,并且比CNN强。其主要问题在于这一类模型的并行能力较差,因为time step的存在,导致每一个时刻的输入必须跟在上一个时刻之后,从而无法使用矩阵进行并行输入。另一方面,ELMo和GPT的提出,正式宣告了迁移学习(预训练+微调)的思想在NLP的引入,并且二者作为动态词向量,逐步代替Word2Vec等静态词向量,解决了“一词多义”的问题。那么,BERT又为何要被提出呢?
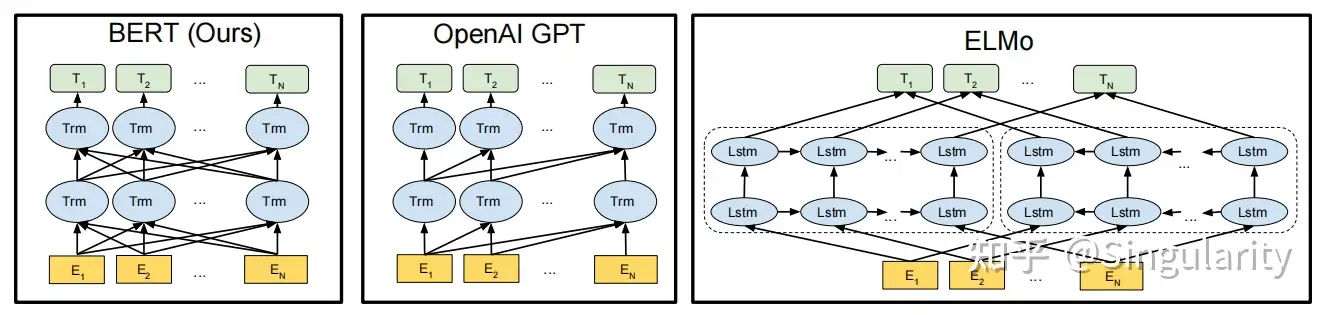
如下图所示,BERT,GPT和ELMo的结构图如下。
BERT、GPT和ELMo
从特征提取器方面来看,ELMo使用的是LSTM,而GPT和BERT用的都是Transformer,只不过前者是用decoder而后者用的是encoder。ELMo使用的LSTM提取语义特征的能力不如Transformer。因此在特征提取方面,GPT和BERT都要更好。
从单双向方面来看,GPT是单向的,剩下二者是双向的。显然,GPT只利用了上文的信息去预测某一个词,效果自然比不过BERT这种利用上下文信息来"完形填空"的做法。另外,ELMo本质上也不能算作真正的利用到了双向的信息,因为它两个模块是分开训练的,即图上显示的这种分别由左向LSTM和右向LSTM来提取特征的方式,并且最终使用拼接(concatenate)的融合方式,效果是不如self-attention的特征融合方式的。在原文中,作者称BERT是"deep bi-directional"。
综上所述,我们可以看出BERT是融合了ELMo和GPT两位"大前辈"的优点而改良得到的。BERT的提出,也轰动了NLP界。
二、BERT是什么?
1. 简介
BERT,全称Bidirectional Encoder Representation of Transformer,首次提出于《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》一文中。简单来说,BERT是使用了Transformer的encoder(即编码器)部分,因此也可以认为BERT就是Transformer的encoder部分。BERT既可以认为是一个生成Word Embedding的方法,也可以认为是像LSTM这样用于特征提取的模型结构。
2. 结构
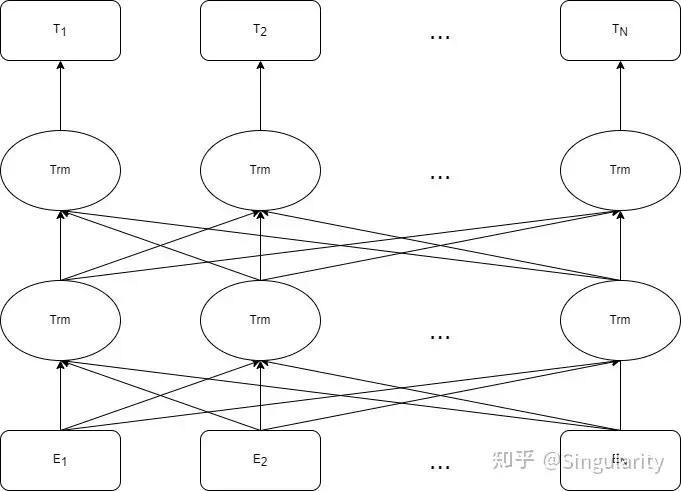
BERT结构
BERT的结构如上图所示。可以看到当Embeddings被输入后,会经过多层的Transformer的encoder(即图中的Trm)进行特征提取。注意!!!这里每一层的所有Trm是共用一套 𝑊𝑞, 𝑊𝑘和𝑊𝑣的,而由于使用了多头注意力机制(Multi-head attention),每一层其实是有多套 𝑊𝑞,𝑊𝑘和𝑊𝑣的。
论文中提出的BERT分为𝐵𝐸𝑅𝑇𝐵𝐴𝑆𝐸和𝐵𝐸𝑅𝑇𝐿𝐴𝑅𝐺𝐸。
参数总量𝐵𝐸𝑅𝑇𝐵𝐴𝑆𝐸:𝐿=12,𝐻=768,𝐴=12,参数总量=110𝑀
参数总量𝐵𝐸𝑅𝑇𝐿𝐴𝑅𝐺𝐸:𝐿=24,𝐻=1024,𝐴=16,参数总量=340𝑀
其中,𝐿代表层数,𝐻代表Hidden size,𝐴代表多头注意力的头数。𝐵𝐸𝑅𝑇𝐵𝐴𝑆𝐸是为了与GPT对比而提出的,而𝐵𝐸𝑅𝑇𝐿𝐴𝑅𝐺𝐸的表现则更优于前者。
1)输入与嵌入

BERT输入
与其他用于NLP任务的模型类似,文本经过分词(tokenization)后,每一个token会在embedding层转化为word embedding,随后再进入模型内部进行后续操作。略微有些不同的是,Bert的输入进入embedding层被分为了三个部分。
Token Embedding
与其他用于NLP问题的模型类似,每个token需要转化为word embedding(词嵌入,亦称word vector词向量),这种结构化的数据才适合作为模型的输入。token embedding的初始化有两种方式。第一种是在预训练时,会生成一个随机初始化的token embedding矩阵。第二种则是更为常见的在预训练模型上微调(fine-tune),在这种情况下就会读取预训练模型预先训练好的embedding矩阵(亦称look-up table),并且在训练过程中进行微调。注意!token embedding的大小是21128*768(中文),30522*768(英文),其中21128和30522分别为中英文vocab的大小,768是word embedding的维度大小。由于模型结构中用到了multi-head self attention机制,使得token embeddings在训练过程中可以学习到上下文信息并以此更新,从而解决一词多义的问题,这也就是BERT被称作动态词向量的原因。在PyTorch中,一般是在定义模型的时候添加这么一句,embedding层中的权重就会跟着更新了。
for param in self.bert.parameters():
param.requires_grad = True举例:
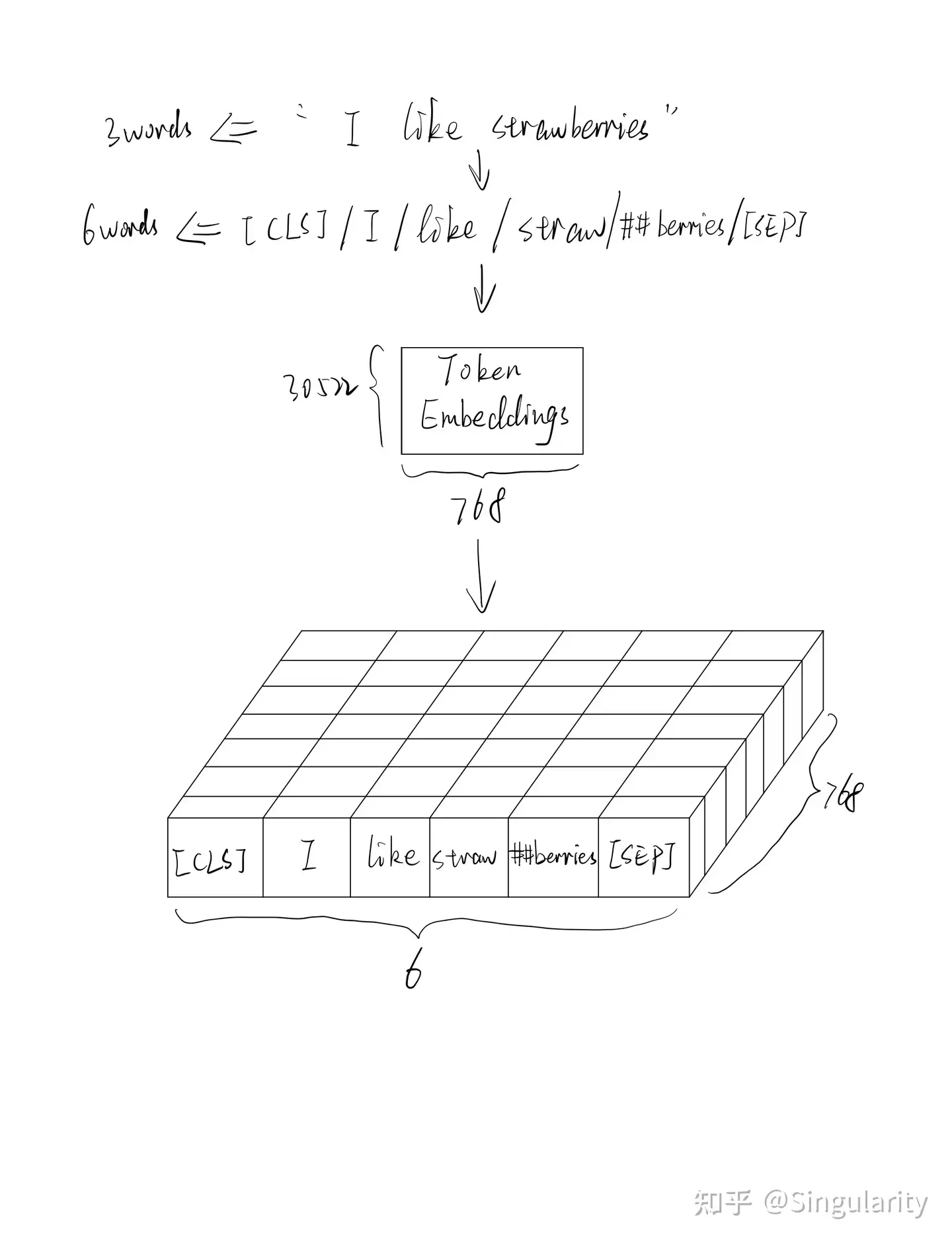
Token Embeddings
值得注意的是,BERT中使用的分词方式是基于WordPiece方法的,并且会添加上[𝐶𝐿𝑆]和[𝑆𝐸𝑃]两个字符。
[𝐶𝐿𝑆]就是classification的意思,一般是放在第一个句子的首位。最后一层的[𝐶𝐿𝑆]字符对应的向量可以作为整句话的语义表示,也就是句向量,从而用于下游的分类任务。使用这个字符是因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。
具体来说,self-attention是用文本中的其它词来增强目标词的语义表示,但是目标词本身的语义还是会占主要部分的,因此,经过BERT的12层,每次词的embedding融合了所有词的信息,可以去更好的表示自己的语义。而[𝐶𝐿𝑆]本身没有语义,经过12层,得到的是attention后所有词的加权平均,相比其他正常词,可以更好的表征句子语义。在Hugging Face中是用pooler_output来返回[𝐶𝐿𝑆]的embedding的。官方描述如下:
this returns the classification token after processing through a linear layer and a tanh activation function. The linear layer weights are trained from the next sentence prediction (classification) objective during pretraining.
源码中,就是将[𝐶𝐿𝑆]的embedding输入一个fc层和一个tanh函数再输出
[𝑆𝐸𝑃] 就是用于输入为句子对时区分两个句子的字符。
关于分词。BERT采用的是WordPiece方法,属于subword level的分词方式,介于word和character两个粒度级别之间。这种级别主要是为了解决word级别存在的问题:
vocabulary过大
通常会存在 out of vocabulary(OOV)的问题
vocabulary中会存在很多相似的词
以及以及character级别中的问题:
文本序列可能会非常长
无法很好对词语的语义进行表征,毕竟单词都被划分为字母了
subword是指对相对低频或者很复杂的词语进行拆分,而对于常见的词语例如"dog"是不会拆分的,而相对较为低频的"dogs"则会拆分。这样做可以使得低频词转化为高频词存储在vocabulary中,从而解决了OOV的问题。同时,转化为常见词以后也可以大大降低vocabulary的大小。例如,只需要存放"boy"、"girl"和"##s"就能够表示"boy"、"girl"、"boys"和"girls"这四个词。关于WordPiece算法的具体实现,可以参考理解tokenizer之WordPiece: Subword-based tokenization algorithm
Segment Embedding
BERT可以用于处理句子对输入的分类问题,简单来说就是判断输入的句子对是否语义相似。而往往我们会将两个句子拼接成一个句子对输入至模型中,segment embedding的作用就是用于标识两个不同的句子。举例如下:
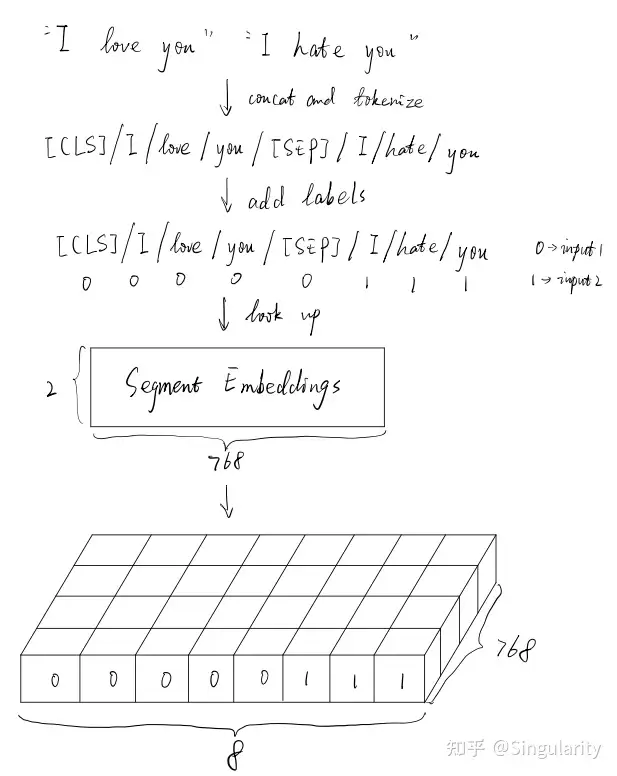
Segment Embeddings
事实上,当用BERT处理非句子对输入的任务,例如文本分类时,只需要将输入文本包括padding(补长)部分全部设为0即可。segment embedding矩阵的大小是2*768。
Position Embedding
跟Transformer类似,多头注意力机制的使用会使得文本输入后丢失位置信息,也就是词序。然而词序对于理解一句话来说是非常重要的,“我爱你”和”你爱我”完全是两种意思。因此position embeddings就是用于标识token的位置,而与Transformer中的不同,BERT中的position embeddings的初始化方式和更新方式与token embedding类似,并且采用的是绝对位置。position embedding矩阵的大小是512*768,因为BERT允许的默认最大长度是512。
Attention masks
事实上,除了以上embeddings之外,在Hugging Face中还有一个参数是需要我们提供的,就是attention mask。关于这个参数,Hugging Face官方文档的解释是
This argument indicates to the model which tokens should be attended to, and which should not.
由于输入是转化成一个个batch的,因此需要靠补长和截断来保持文本长度的统一,而补长部分是不需要参与attention操作的。1代表需要参与attention的token,而0表示补长的部分。
代码实例
text = ['今天天气很好','我觉得很不错这款B48发动机很不错']
for txt in text:
encoding_result = tokenizer.encode_plus(txt, max_length=10, padding='max_length', truncation = True)
print(encoding_result)
[{'input_ids': [101, 791, 1921, 1921, 3698, 2523, 1962, 102, 0, 0], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 0, 0]},
{'input_ids': [101, 2769, 6230, 2533, 2523, 679, 7231, 6821, 3621, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}]上述例子展示的是两个长短不一致的文本经过tokenizer转换后得到的结果。input_ids是指每个token在vocab中的序号,用这个序号在token embedding矩阵中去查找对应的词嵌入。本质上就是将序号转化为one-hot vector,然后再与embedding矩阵相乘,从而得到矩阵中的某一行/列,这个行/列向量即为所求,这种操作就是look up,这种embedding矩阵也称为look-up table。类似的,token_type_ids则是用于查找segment embedding的,而attention_mask就只是用于标识是否需要attention操作,不会转化为向量。那么position_ids呢?它则是由模型自动生成的,会在模型的forward()函数中生成。Hugging Face官方文档是这样描述的:
position_ids — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range [0,𝑐𝑜𝑛𝑓𝑖𝑔.𝑚𝑎𝑥_𝑝𝑜𝑠𝑖𝑡𝑖𝑜𝑛_𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔𝑠−1].
此处的config.max_position_embeddings默认为512,也可以调成1024或者2048。
总结
BERT的输入包含三种embedding:token embedding、segment embedding和position embedding,都是由对应的id做look up操作而得的。其中position_ids是可以由模型自己生成的。值得注意的是,BERT中生成的position embedding的方式类似于word embedding的生成方式,也被称为parametric(参数式),对应的则是Transformer中的functional(函数式)。得到三种embedding之后,模型会将三者相加,一并输入模型中做后续操作。为什么这三个embedding可以相加呢?不会改变向量原本的方向从而失去一定语义信息吗?事实上,这种element-wise summation就等同于先将三种embedding向量拼接在一起,然后再与一个大的look-up table相乘,这种拼接本质上就是做特征融合。举个例子,某个token的三种独热向量分别是[0,1,0,0]、[1,0]和[1,0,0]。下图是三个向量分别和矩阵做乘法最后相加得到的结果。
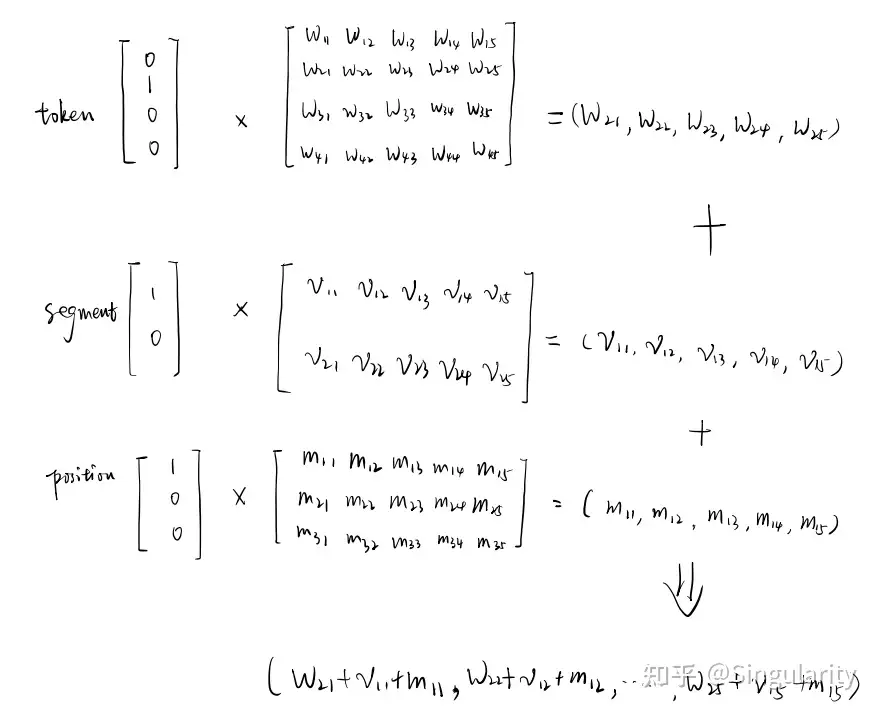
下图则是三个向量先做拼接后再与一个由上述三个矩阵拼接而成的大矩阵相乘得到的结果。
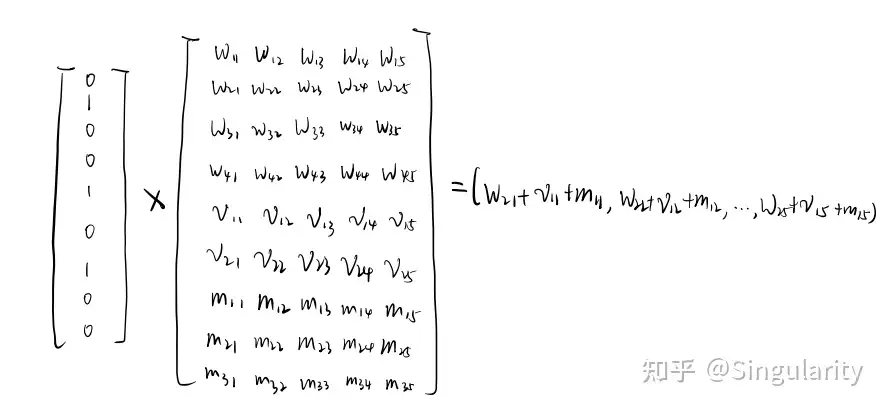
可以看到,这两种方式得到的结果是一致的。因此可以认为三个embedding相加就是在做特征融合。
2) 中间层
从上面结构图可知,中间部分采用的是Transformer的encoder。encoder的结构如下。
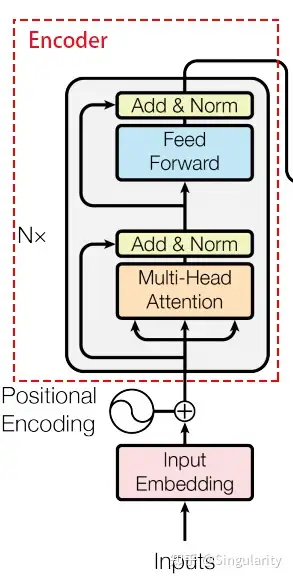
Transformer的encoder部分
Multi-head Attention
多头自注意力机制是BERT最关键的部分之一。略微不同的是,在微调阶段,BERT的几个矩阵中的权值都是预先训练好的,仅需在下游任务训练时进行微调。
Add&Norm
这部分看起来就两个词,实际上包含了两种机制/技术。一是skip connect残差连接,二是Layer Normalization层标准化。通常认为,残差连接在《Deep Residual Learning for Image Recognition》被提出后广受欢迎。它的作用就在于减缓反向传播时导致的梯度消失以及深层网络的退化现象。下图展示了残差连接的结构,BERT中的add指的就是将原输入与经过多头自注意力机制之后的结果相加起来。
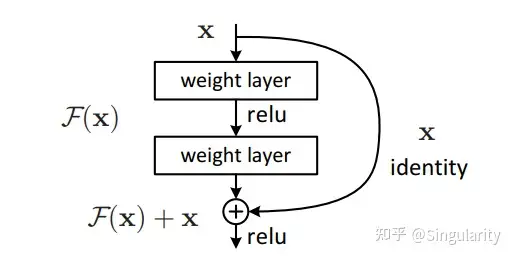
残差连接
Layer Normalization,即层标准化,是对应于Batch Normalization的另一种标准化方式,在《Layer Normalization》中被提出。与Batch Normalization不同的是,Layer Normalization是对于同一层中所有节点进行标准化,在NLP问题中就是对某一个词的向量进行标准化。原文中用以下的公式来对第𝑙层进行Layer Normalization: 𝜇𝑙=1𝐻Σ𝑖=1𝐻𝑎𝑖𝑙𝜎𝑙=1𝐻Σ𝑖=1𝐻(𝑎𝑖𝑙−𝜇𝑙)2𝑦=𝑔𝜎𝑙⊙(𝑥𝑙−𝜇𝑙)+𝑏 其中$H$代表这一层中节点的个数,即词向量的维度,𝑔和𝑏分别叫做gain和bias参数,用于仿射变换,实际上就是乘以𝑔做放缩,再加上𝑏做平移。而在PyTorch中是用下面这个公式去计算的
𝑦=𝑥−𝐸[𝑥]𝑉𝑎𝑟[𝑥]+𝜖∗𝛾+𝛽
𝜖 是一个非常小的数,作用是防止分母为0,𝛾和𝛽就是上述两个参数。PyTorch中nn.LayerNorm类的定义如下:
torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True, device=None, dtype=None)举个例子来说明这个类怎么用。
text = torch.FloatTensor([[[1,3,5],
[1,7,8]],
[[2,4,6],
[3,2,1]]])
layer_norm = nn.LayerNorm(3)
print(layer_norm(text))
tensor([[[-1.2247, 0.0000, 1.2247],
[-1.4018, 0.5392, 0.8627]],
[[-1.2247, 0.0000, 1.2247],
[ 1.2247, 0.0000, -1.2247]]], grad_fn=<NativeLayerNormBackward0>)text是一个2*2*3的张量,可以理解为batch*seq_len*embedding_dim,即batch数为2,文本长度为2,词向量维度为3。我们可以看到,输出也是一个2*2*3的张量,那么其中元素数值是怎么算的呢?此时normalised_shape参数传入的是3,即输入维度最后一维的size,那么就会沿着最后一维求出均值𝐸[𝑋]和方差𝑉𝑎𝑟[𝑥]。此处 𝐸[𝑥]=[316342] 𝑉𝑎𝑟[𝑥]=[838698323]
再根据上述公式计算Layer Normalization之后的值。举个例子,第1行(从0开始)第0列的1−163=−133,除以869+0.00001,得到的就是-1.4018。注意,此时elementwise_affine为True,weight和bias参数的shape和normalised_shape是一致的,二者中的元素分别初始化为1和0。而当elementwise_affine为False时,得到的结果如下。此时是少了两个可学习的参数,并且不参与梯度计算。关于Normalization可以参考
tensor([[[-1.2247, 0.0000, 1.2247],
[-1.4018, 0.5392, 0.8627]],
[[-1.2247, 0.0000, 1.2247],
[ 1.2247, 0.0000, -1.2247]]])值得注意的是,Add&Norm这部分在代码中实际上还包括dropout,原文作者有提到dropout之后的效果更好。
Feed Forward
Transformer模型原文中的公式是 𝐹𝐹𝑁(𝑥)=𝑚𝑎𝑥(0,𝑥𝑊1+𝑏1)𝑊2+𝑏2 实际上就是两层全连接层,中间隐层用的激活函数是ReLU函数。在PyTorch中的代码实现如下:
class FeedForward(nn.Module):
'''
原文中隐层维度为3072,输入和输出维度即d_model = 768
'''
def __init__(self, input_dim, hidden_dim = 2048):
super(FeedForward,self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, input_dim)
def forward(self, x):
out = self.fc1(x)
out = F.relu(out)
out = self.fc2(out)
return out而不一样的是,在BERT模型中,使用的激活函数是GELU。GELU,高斯误差线性单元激活函数Gaussian Error Linear Units,可以被看作是ReLU函数的平滑版,毕竟ReLU并非处处可导。在BERT源码中是这样写的
def gelu(input_tensor):
cdf = 0.5 * (1.0 + tf.erf(input_tensor / tf.sqrt(2.0))) #用erf函数近似
return input_tesnsor*cdf下图展示了GELU与ReLU函数的对比图,橙色的是GELU函数,蓝色的是ReLU函数。可以看到,GELU函数在0点处是可导的。
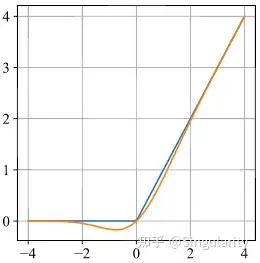
GELU与ReLU
3) 输出层
根据Hugging Face的官方文档,BERT本身的输出的有四个。
last_hidden_state:这是模型最后一层输出的隐藏状态,shape是[batch_size, seq_len, hidden_dim],而hidden_dim = 768
pooler_output:这就是$[CLS]$字符对应的隐藏状态,它经过了一个线性层和Tanh激活函数进一步的处理。shape是[batch_size, hidden_dim]
hidden_states:这是可选项,当output_hidden_states = True时会输出。它是一个包含了13个torch.FloatTensor的元组,每一个张量的shape均为[batch_size, seq_len, hidden_dim]。根据文档,这13个张量分别代表了嵌入层和12层encoder的输出.例如hidden_states[0]就代表嵌入层的输出,hidden_states[12]就是最后一层的输出,即last_hidden_state
attentions:这是可选项,当output_attentions = True时会输出。它是一个12个torch.FloatTensor元组,包含了每一层注意力权重,即经过自注意力操作中经过Softmax之后得到的矩阵。每一个张量的shape均为[batch_size, num_head, seq_len, seq_len]
由于BERT是一个预训练模型,因此最终的输出层是根据下游任务不同而变化的。下图是BERT原文中展示的几个下游任务以及BERT是怎么做的。句子对分类任务以及单句的分类任务都是通过[𝐶𝐿𝑆]字符输出class label的,一般来说后面接个全连接层就可以将向量从768维映射为目标维数,再接一个Softmax函数就可以变为概率分布,从而完成分类。上文提到,[𝐶𝐿𝑆]可以理解为整个句子的句向量,因此可以用作分类任务。(d)中提到的则是实体标注的任务,即对句子中每个token的词性或者其他属性进行标注,因此需要对每个token都进行输出。
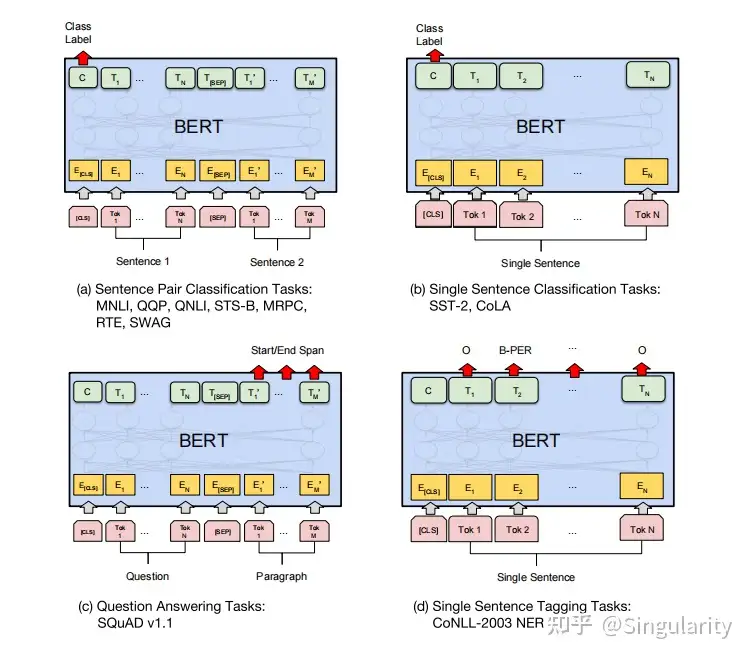
BERT用于各种任务上
(c)中展示的是BERT用于问答任务(其实是阅读理解)。在此类任务中,BERT要求将问题和答案所在参考文本拼接在一起,中间用[𝑆𝐸𝑃]作为分隔。此处可以当成句子对的任务来看,因此需要显式指定 𝑠𝑒𝑔𝑚𝑒𝑛𝑡_𝑖𝑑。
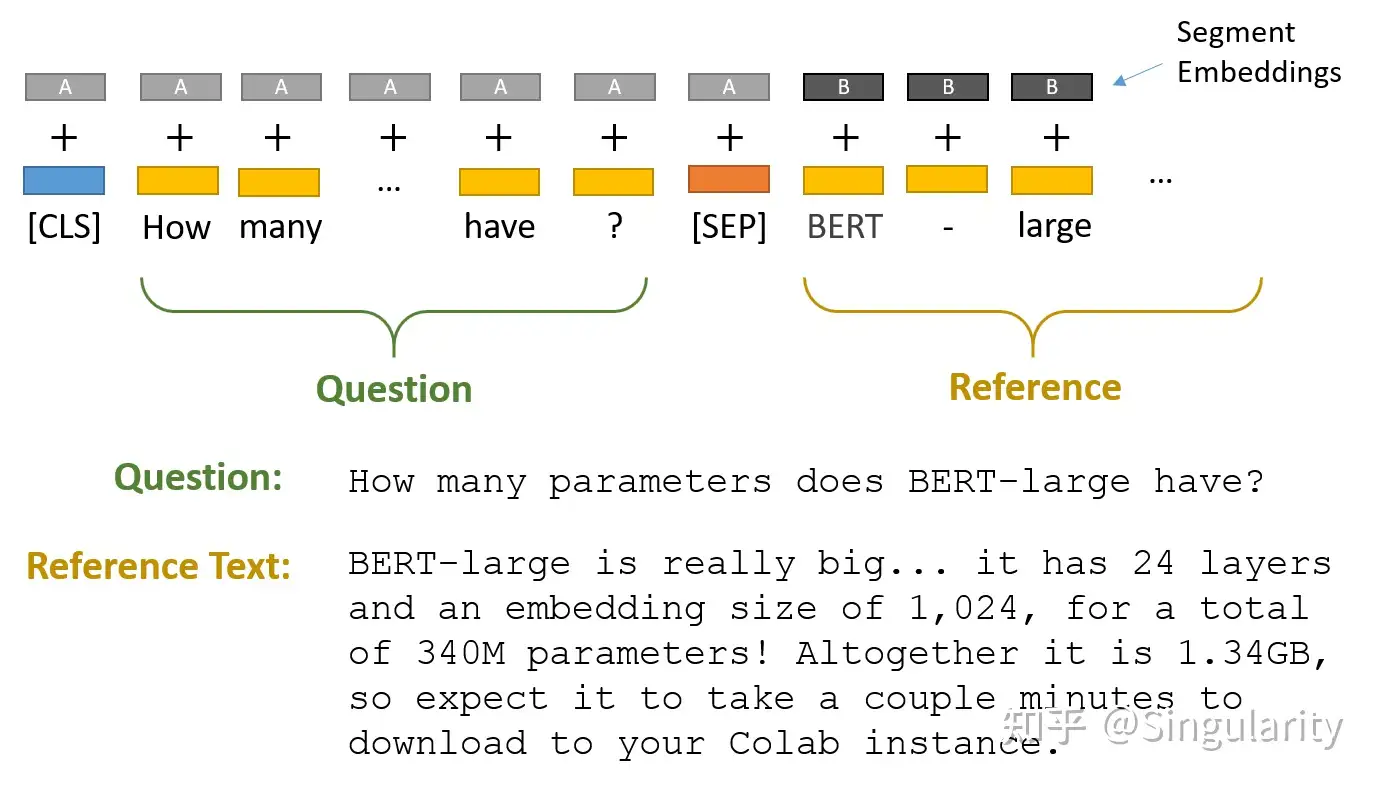
BERT阅读理解
那么BERT是怎么从文本中找到对应答案的呢?BERT是将某一个范围的文本"高亮"出来,以表示选出来的答案。这本质上就是预测哪个token作为开始,哪个token作为结束。下图描述的是将文本中每一个token对应的最终embedding向量与start token分类器的权重做点乘,再经过Softmax函数得到概率分布,以此选出得分最高的token作为start token。这个start token分类器只有一套权重,作用于文本中每一个token。同样地,end token也是这么被找到的,只不过用的是end token分类器。

start token
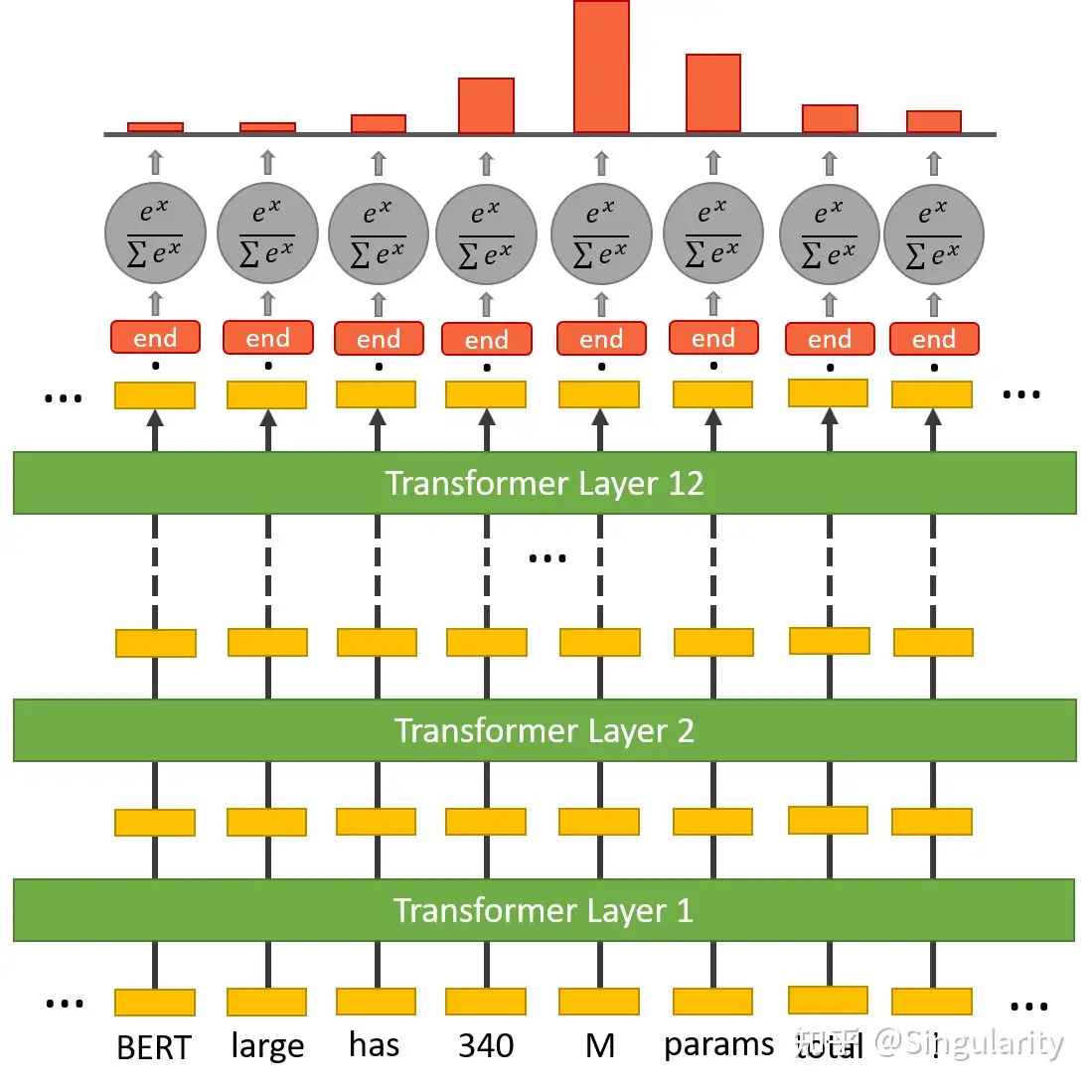
end token
三、BERT是怎么进行预训练的?
上文提到,BERT属于预训练模型,而根据下游任务的不同再进行微调。当然,也可以选择不微调,Huggingface的Transformer库里提供了很多已经可以直接拿来解决不同下游任务的预训练模型,例如BertForQuestionAnswering,BertForSequenceClassification等等。那么BERT是怎么进行预训练的呢?BERT是针对两个任务进行预训练的。
1. Masked Language Model
简单来说,这个预训练任务就是一个完型填空的任务,即通过上下文判断出某一位置应该是什么词。这一任务是受到了ELMo和GPT的启发。在GPT中,训练语言模型的时候用的是Decoder,这就导致它有一个必须从左到右预测的限制,因为解码器中存在masked multi-head attention。因此,GPT只训练出提取上文信息预测下文的能力,而没有使用下文。而ELMo看上去用了双向,但实际上是分别以𝑃(𝑤𝑖|𝑤1,𝑤2,⋯,𝑤𝑖−1)和𝑃(𝑤𝑖|𝑤𝑖+1,⋯,𝑤𝑛)作为目标函数,这两个目标函数在训练过程中都只考虑了单向的上文或下文,只是在得到representation时拼接在一起。但BERT不一样,它是以𝑃(𝑤𝑖|𝑤1,⋯,𝑤𝑖−1,𝑤𝑖+1,⋯,𝑤𝑛)作为目标函数的,也就是考虑了上下文。
原文中,作者在输入的序列里随机选中15%的词用[𝑀𝐴𝑆𝐾]字符替换掉,然后让BERT去预测这个词。但后来这也导致了一个问题:在微调阶段$[MASK]$字符是不会出现的,所以就产生了不匹配。因此,作者对这15%的词做了以下改动:
其中80%仍用$[MASK]$字符替换
10%用随机的词语替换
10%保持原来的词
细节
引入[𝑀𝐴𝑆𝐾]字符是为了显示地告诉模型“当前这个词你得从上下文去推断,我不会告诉你”。实际上这就是一种Denoising Autoencoder的思路,那些被替换掉的位置就相当于引入了噪音,BERT的这种预训练方式也被称为DAE LM(Denosing Autoencoder Language Model)。
为什么这15%的词不能全部都用[𝑀𝐴𝑆𝐾]去替换?倘若这么做,在微调阶段,模型见到的都是正常的词语而没有[𝑀𝐴𝑆𝐾],它就只能完全基于上下文信息来推断当前词,而无法利用当前词本身的信息,毕竟它们从未在预训练阶段出现过。
为什么要引入随机词语?如果按照80%用[𝑀𝐴𝑆𝐾]字符,剩下20%用于原词语,那么模型就会学到“如果当前词语是[𝑀𝐴𝑆𝐾],那么就从上下文去推断;如果当前词语是一个正常词语,那么答案就是这个词“这一模式。这样一来,在微调阶段模型见到的都是正常的词语,模型就直接”照抄“所有的词,而不会提取上下文的信息了。以一定概率引入随机词语,就是想让模型无论什么情况下,都要把当前token信息和上下文信息结合起来,从而在微调阶段才能提取这两方面的信息,因为它不知道当前的词语是否是”原来的词“。并且,随机词语的替换仅占1.5%(10%*15%),因此对于模型的语言理解能力没有什么影响。
2. Next Sentence Prediction
此任务是让模型预测下一个句子是否真的是当前句子的下一句。起因是很多重要的下游任务例如问答(QA)和自然语言推理(NLI)都基于两个句子之间的关系,因而此任务就可以使得模型学习提取两个句子之间关系的能力。具体做法如下:
选择句子A和B作为输入,将两个句子首尾相接拼接起来,中间用[𝑆𝐸𝑃]连接。
其中50%的时间里,选择的B是A的真实的下一句。
剩下50%的时间里,随机选择B,只要不是A的下一句即可。 下图即为NSP任务的一个例子

Next Sentence Prediction的例子
3. 关于MLM和NSP的其他问题
损失函数
BERT的损失函数由两部分组成:MLM任务的损失函数+NSP任务的损失函数,用公式表示即为:
𝐿(𝜃,𝜃1,𝜃2)=𝐿1(𝜃,𝜃1)+𝐿2(𝜃,𝜃2)
其中𝜃指的是encoder部分中的参数, 𝜃1指的是MLM任务在encoder部分之后接的输出层中的参数, 𝜃2指的是NSP任务中encoder后接上的分类器的参数。
而对于MLM任务,实际上也就是一个分类的任务。倘若所有被遮盖/替换的词语的集合是M,而vocabulary的长度为|𝑉|,那么这就是一个|𝑉|分类的问题。下面这个公式就是负对数似然函数,最小化这个函数就等同于最大似然估计,即求得一组𝜃和𝜃1,使得N个 𝑚𝑖 出现的概率最大。
𝐿1(𝜃,𝜃1)=−Σ𝑖=1𝑁log𝑝(𝑚=𝑚𝑖|𝜃,𝜃1),𝑚𝑖∈[1,2,...,|𝑉|]
再来看看NSP任务的损失函数。NSP可以看作是一个二分类的文本分类任务,只需要将[𝐶𝐿𝑆]的输出接入一个全连接层作为分类器。
𝐿2(𝜃,𝜃2)=−Σ𝑗=1𝑁log𝑝(𝑛=𝑛𝑖|𝜃,𝜃2),𝑛𝑖∈[𝐼𝑠𝑁𝑒𝑥𝑡,𝑁𝑜𝑡𝑁𝑒𝑥𝑡]
加在一起就是
𝐿(𝜃,𝜃1,𝜃2)=−Σ𝑖=1𝑁log𝑝(𝑚=𝑚𝑖|𝜃,𝜃1)−Σ𝑗=1𝑁log𝑝(𝑛=𝑛𝑖|𝜃,𝜃2)
其他细节
借鉴Adherer要加油呀~ 的说法,具体的预训练工程实现细节方面,BERT 还利用了一系列策略,使得模型更易于训练,比如对于学习率的 warm-up 策略,使用的激活函数不再是普通的 ReLu,而是 GeLu,也使用了 dropout 等常见的训练技巧。
由上述损失函数可以推断出来,MLM和NSP这两个预训练是联合训练的,也就是一起训练的。
在BERT后续的变体模型RoBERTa的论文里,被提出NSP这个预训练任务不但没有使下游任务微调时有明显的受益,甚至还会有负面作用,所以干脆直接不用NSP了。
四、如何使用BERT?
下面用一个简单的例子来展示bert_case_chinese这个预训练模型是怎么用的,其他版本的也都是大同小异了。以下内容参考Pytorch-Bert预训练模型的使用(调用transformers)。
首先下载transformers模块,这个模块包含了很多NLP和NLU中会使用的预训练模型,包括BERT、GPT-2、RoBERTa等等。从transformers模块中引入BertModel、BertTokenizer和BertConfig类。同时还需要引入torch模块。
!pip install transformers
from transformers import BertModel, BertTokenizer, BertConfig
import torch值得注意的是,由于我使用的是Google Colab平台,直接from transformers import BertModel会从官方的s3数据库下载模型配置、参数等信息,这在大陆并不可用。因此一般来说就需要手动下载模型,下载bert-base-chinese,里面包含config.josn,vocab.txt,pytorch_model.bin三个文件,将其放在对应的文件夹内。
下面则是导入分词器、配置和模型
#通过词典导入分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
#导入配置文件
model_config = BertConfig.from_pretrained('bert-base-chinese')
#修改配置
model_config.output_hidden_states = True
model_config.output_attentions = True
#通过配置和模型id来导入模型
model = BertModel.from_pretrained('bert-base-chinese', config = model_config)接着开始分词。此处设定最大长度为10,过长的会被截断,而不够长的会用[𝑃𝐴𝐷]补长
text = ['你真的很好看。','这个牌子的咖啡很好喝。']
encoding_results = list()
for txt in text:
encoding_results.append(tokenizer.encode_plus(txt, max_length = 10, padding = 'max_length', truncation = True))
print(encoding_results)
[{'input_ids': [101, 872, 4696, 4638, 2523, 1962, 4692, 102, 0, 0], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 0, 0]},
{'input_ids': [101, 6821, 702, 4277, 2094, 4638, 1476, 1565, 2523, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}]打印的结果就是encode_plus()返回的结果。encode_plus()返回的是两个字典,每个字典包含以下三个元素:
input_ids:每个token在词典中的index。例如此处[𝐶𝐿𝑆]和[𝑆𝐸𝑃]token分别对应的是101和102,而补长的token则是0。
token_type_ids:上文提到的用于查找segment embedding的id,即用于区分两个句子的编码。
attention_mask: 指定对于哪些token进行attention操作。例如此处第一个句子最后补长的部分则不进行attention操作。
除此之外,也可以用encode()来进行分词,只不过只会返回input_ids。接着让我们看看分词后句子变成了什么。
for res in encoding_results:
print(tokenizer.convert_ids_to_tokens(res['input_ids']))
['[CLS]', '你', '真', '的', '很', '好', '看', '[SEP]', '[PAD]', '[PAD]']
['[CLS]', '这', '个', '牌', '子', '的', '咖', '啡', '很', '[SEP]']可以看到,文本被切分成一个个的字,首尾分别添加上了[𝐶𝐿𝑆]和[𝑆𝐸𝑃]字符,并且补偿部分用的是[𝑃𝐴𝐷]字符。接着将字典中的三个元素取出来,放入列表后组成张量作为模型输入。
input_ids = list()
type_ids = list()
mask_ids = list()
for res in encoding_results:
input_ids.append(res['input_ids'])
type_ids.append(res['token_type_ids'])
mask_ids.append(res['attention_mask'])
#将三个列表转化为张量
input_ids = torch.tensor(input_ids)
type_ids = torch.tensor(type_ids)
mask_ids = torch.tensor(mask_ids)输入模型之后,得到返回值。返回值是一个字典,我们先查看它的keys。
outputs = model(input_ids, token_type_ids = type_ids, attention_mask = mask_ids)
print(outputs.keys())
#odict_keys(['last_hidden_state', 'pooler_output', 'hidden_states', 'attentions'])可以看到,keys包含了上述的四个输出,由于config部分将两个参数调为了True,因此也会输出hidden_states和attentions。至此,关于BERT如何使用的部分就结束了。现在看看输出部分。
print(outputs['last_hidden_state'].shape)
print(outputs['pooler_output'].shape)
torch.Size([2, 10, 768])
torch.Size([2, 768])刚好对应上batch_size = 2, seq_len = 10和hidden_dim = 768。
print(len(outputs['hidden_states']))
print(len(outputs['attentions']))
print(outputs['hidden_states'][8].shape)
print(outputs['attentions'][1].shape)
13
12
torch.Size([2, 10, 768])
torch.Size([2, 12, 10, 10])前两个结果说明,attentions是不算上embedding层的,因此只有12个元素;而hidden_states则是包含了embedding层的输出,所以一共有13个元素。另外后两个结果也正好对应了上文的shape。另外,如果下游任务需要进行微调,就需要定义优化器和损失函数。损失函数根据不同下游任务有不同的选择,例如多分类任务可以使用交叉熵函数;而优化器一般选择的是𝐴𝑑𝑎𝑚𝑊优化器。
五、一些细节
1. Feature-based和Fine-tuning
在BERT的论文中,作者提到了ELMo是属于Feature-based,而GPT和BERT属于Fine-tuning(当然,BERT也可以用feature-based方法)。
Feature-based就是通过训练神经网络语言模型,而其中的权重是可以拿来当作词语的embedding的。简单来说,feature-based要的不是整个语言模型,而是其中的”中间产物”,即embedding,再用这些embedding去作为下游任务的输入。最经典的例子就是ELMo和Word2Vec。
对于静态词向量例如Word2Vec和Glove,其做法就是查表。也就是输入某一个词的one-hot编码,然后查找对应的词向量,并且得到的词向量用以下游任务;对于动态词向量例如ELMo和BERT,是将下游任务的数据输入至模型中,得到每个词的embedding,再用于下游任务中。由此也可以看出,静态词向量是指在训练后不再发生改变,而动态词向量会根据上下文的不同而变化。
Feature-based方法分为两个步骤:
首先在大的语料A上无监督地训练语言模型,训练完毕得到语言模型。
然后构造task-specific model例如序列标注模型,采用有标记的语料B来有监督地训练task-sepcific model,将语言模型的参数固定,语料B的训练数据经过语言模型得到LM embedding,作为task-specific model的额外特征。
Fine-tuning则不同,此类方法是将整个模型拿过来,再根据下游任务的不同进行添加或者修改,使其输出符合任务需要。一般来说都是在模型的最后一层或者现有模型结构之后添加上一层网络结构以匹配各种下游任务。GPT-1、GPT-2和BERT就用到了Fine-tuning。
Fine-tune分为两个步骤:
构造语言模型,采用大的语料A来训练语言模型
在语言模型基础上增加少量神经网络层来完成specific task例如序列标注、分类等,然后采用有标记的语料B来有监督地训练模型,这个过程中语言模型的参数并不固定,依然是trainable variables。
2. BERT是如何解决一词多义问题的?
所谓一词多义,就是指相同的词在不同上下文语境中有可能意思不同。例如"这个苹果真好吃"和“今年苹果手机又涨价了”,这其中的“苹果”一词代表的就是不同意思。而静态词向量如Word2Vec和GloVe,训练好之后是通过查表(即look up)的方式取得对应的词向量的,在这种情况下词向量是固定的,因此不论上下文怎么变化,使用的都是这个词向量。
上文提到,BERT是动态词向量,因此可以解决一词多义的问题。这是因为对于某一个词,BERT会让其学习到上下文信息并结合自身信息,因此经过十二层encoder之后得到的词向量就会根据上下文的不同而改变,这是多头注意力机制的作用。
3. BERT的双向体现在哪里?
BERT的全称是Bidirectional Encoder Representation of Transformer,其双向就体现在encoder做self-attention操作时除了当前的词/token以外,还同时使用了上下文的词/token作为输入,同时学习到了上文和下文的信息,这也是MLM任务的作用。
4. BERT的参数量
此处以𝐵𝐸𝑅𝑇𝐵𝐴𝑆𝐸为例
输入部分的参数量:(30522+2+512)*768
中间层对于每一个encoder(算上bias):
attention机制的参数=768*768/12*3*12(12个头)+768/12*12*3
将每个头拼接在一起并经过一个全连接层= 768/12*12*768+768
LayerNorm层参数=768+768
两层前馈层=768*3072+3072+3072*768+768
LayerNorm层参数=768+768
中间层参数求和后乘以12,最终得到108890112,即约为110M。
5. BERT在预训练时构造的样本长度
为了不浪费算力同时也节省训练时间,在预训练阶段,BERT在前90%的时间里都将样本长度设定为128,后10%的时间为了训练位置编码才设定为512。
6. BERT的每一层都学到了什么?
关于这一点可以参考此文ACL 2019 | 理解BERT每一层都学到了什么,原论文为What does BERT learn about the structure of language?。
7. 其他
关于其他细节,可以参考关于BERT中的那些为什么。