

Attention Is All You Need - 1706.03762v7
01 算法介绍前的说明
由于该文章提出是解决NLP(Nature Language Processing)中的任务,例如文章实验是在翻译任务上做的。为了CV同学更好的理解,先简单介绍一下NLP任务的一个工作流程,来理解模型的输入和输出是什么。
1.1 CV模型的输入和输出
首先拿CV中的分类任务来说,训练前我们会有以下几个常见步骤:
获取图片
定义待分类的类别,用数字标签或者one-hot向量标签表示
对图片进行类别的标注
图片预处理(翻转、裁剪、缩放等)
将预处理后的图片输入到模型中
所以对于分类任务来说,模型的输入为预处理过的图片,输出为图片的类别(一般为预测的向量,然后求argmax获得类别)。
1.2 NLP模型的输入
在介绍NLP任务预处理流程前,先解释两个词,一个是tokenize,一个是embedding。
tokenize是把文本切分成一个字符串序列,可以暂且简单的理解为对输入的文本进行分词操作。对英文来说分词操作输出一个一个的单词,对中文来说分词操作输出一个一个的字。(实际的分词操作多有种方式,会复杂一点,这里说的只是一种分词方式,姑且这么定,方便下面的理解。)
embedding是可以简单理解为通过某种方式将词向量化,即输入一个词输出该词对应的一个向量。(embedding可以采用训练好的模型如GLOVE等进行处理,也可以直接利用深度学习模型直接学习一个embedding层,Transformer模型的embedding方式是第二种,即自己去学习的一个embedding层。)
在NLP中,拿翻译任务(英文翻译为中文)来说,训练模型前存在下面步骤:
获取英文中文对应的句子
定义英文词表(常用的英文单词作为一个类别)和中文词表(一个字为一个类别)
对中英文进行分词
将分好的词根据步骤2定义好的词表获得句子中每个词的one-hot向量
对每个词进行embedding(输入one-hot输出与该词对应的embedding向量)
embedding向量输入到模型中去
所以对于翻译任务来说,翻译模型的输入为句子每个词的one-hot向量或者embedding后的向量(取决于embedding是否是翻译模型自己学习的,如果是则输入one-hot就可以了,如果不是那么输入就是通过别的模型获得的embedding向量)组成的序列,输出为当前预测词的类别(一般为词表大小维度的向量)。
02 Transformer的结构
知道了Transformer模型的输入和输出后,下面来介绍一下Transformer模型的结构。
先来看看Transformer的整体结构,如下图所示:
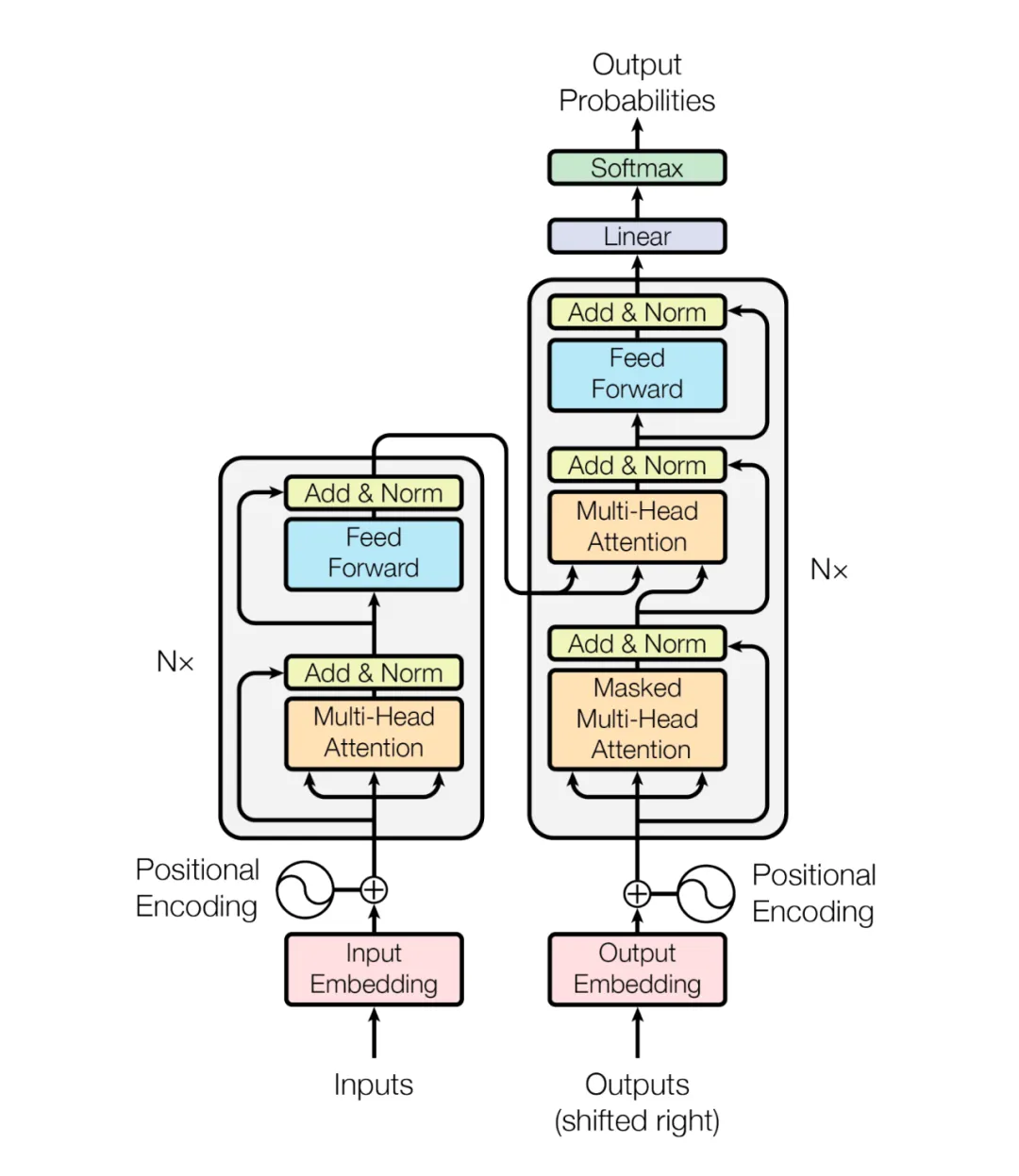
可以看出它是一个典型的seq2seq结构(encoder-decoder结构),Encoder里面有N个重复的block结构,Decoder里面也有N个重复的block结构。
2.1 Embedding
可以注意到这里的embedding操作是与翻译模型一起学习的。所以Transformer模型的输入为对句子分词后,每个词的one-hot向量组成的一个向量序列,输出为预测的每个词的预测向量。
2.2 Positional Encoding
为了更好的利用序列的位置信息,在对embedding后的向量加上位置相关的编码。文章采用的是人工预设的方式计算出来的编码。计算方式如下
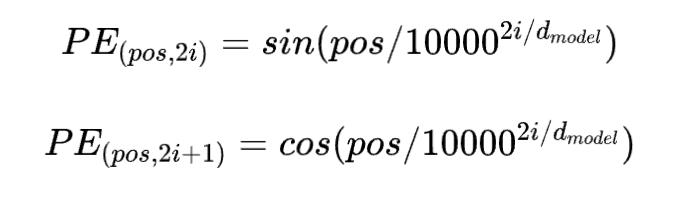 上式中,pos表示当前词在句子中的位置,例如输入的序列长L=5,那么pos取值分别为0-4,i表示维度的位置,偶数位置用公式计算, 奇数位置用公式计算。
上式中,pos表示当前词在句子中的位置,例如输入的序列长L=5,那么pos取值分别为0-4,i表示维度的位置,偶数位置用公式计算, 奇数位置用公式计算。
文章也采用了加入模型训练来自动学习位置编码的方式,发现效果与人工预设方式差不多。
2.3 Encoder结构
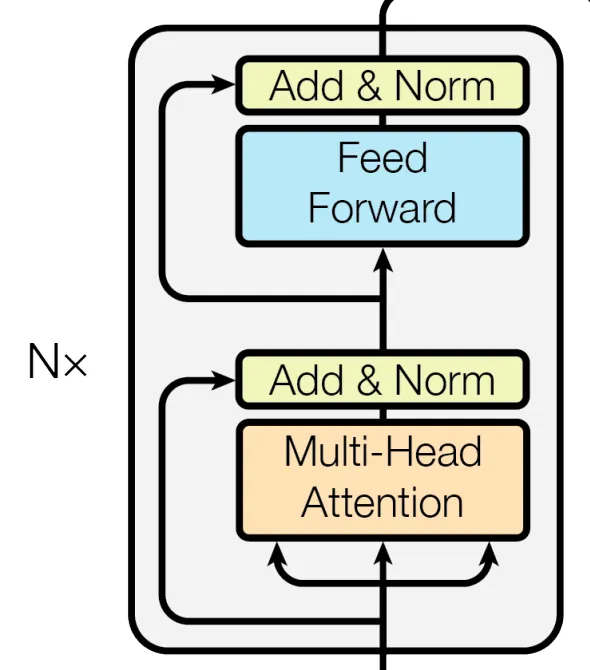
Encoder包含了N个重复的block结构,文章N=6。下面来拆解一个每个块的具体结构。
2.3.1 Multi-Head Attention(encoder)
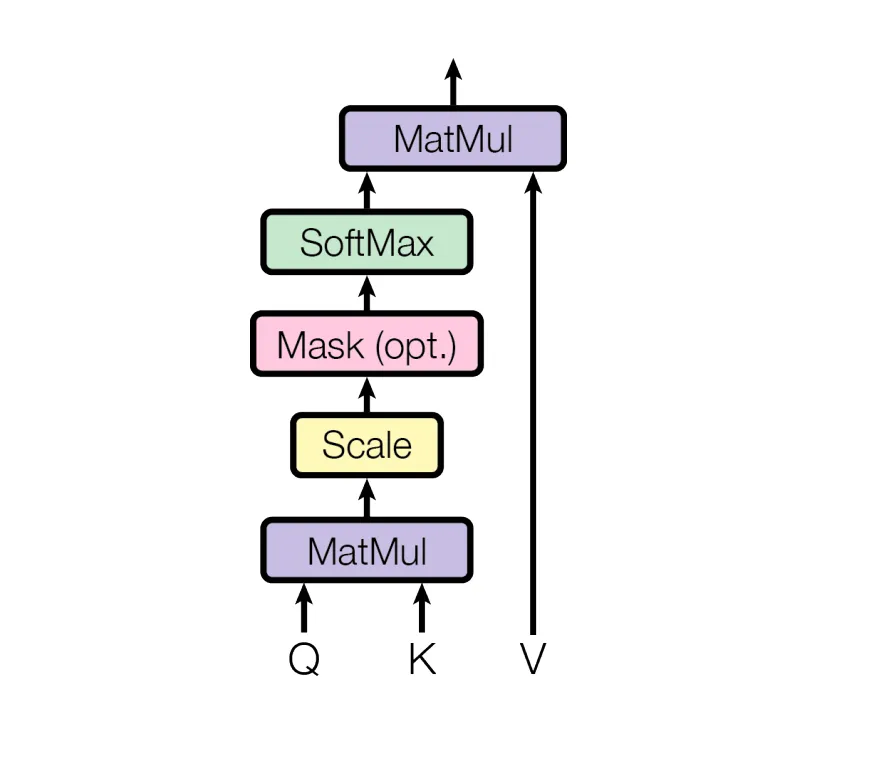
为了便于理解,介绍Multi-Head Attention结构前,先介绍一下基础的Scaled Dot-Product Attention结构,该结构是Transformer的核心结构。
Scaled Dot-Product Attention结构如下图所示:
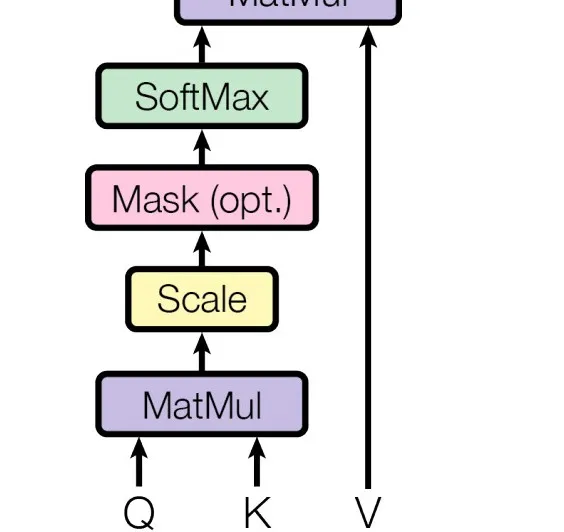
Scaled Dot-Product Attention模块用公式表示如下
上式中,可以假设Q\K的维度皆为,V的维度为,L为输入的句子长度,,为特征维度。
得到的维度为,该张量可以理解为计算Q与K中向量两两间的相似度或者说是模型应该着重关注(attention)的地方。这里还除了,文章解释是防止维度太大得到的值就会太大,导致后续的导数会太小。(这里为什么一定要除而不是或者其它数值,文章没有给出解释。)
经过获得attention权重后,与V相乘,既可以得到attention后的张量信息。最终的输出维度为
这里还可以看到在Scaled Dot-Product Attention模块中还存在一个可选的Mask模块(Mask(opt.)),后续会介绍它的作用。
文章认为采用多头(Multi-Head)机制有利于模型的性能提高,所以文章引入了Multi-Head Attention结构。
Multi-Head Attention结构如下图所示
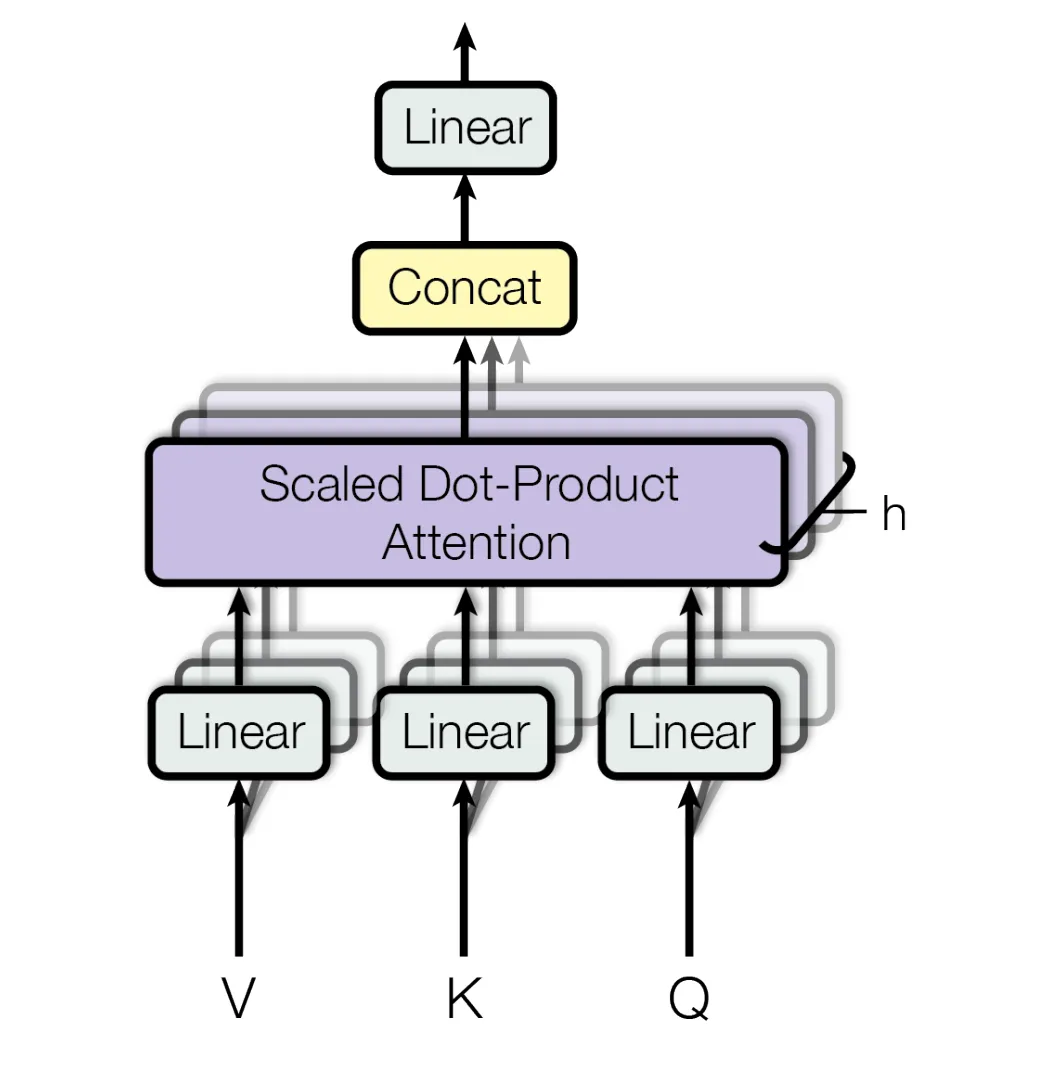
Multi-Head Attention结构用公式表示如下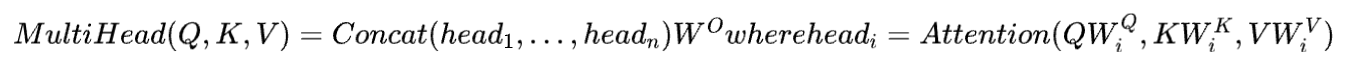 关于multi-head机制为什么可以提高模型性能
关于multi-head机制为什么可以提高模型性能
文章末尾给出了多头中其中两个头的attention可视化结果,如下所示
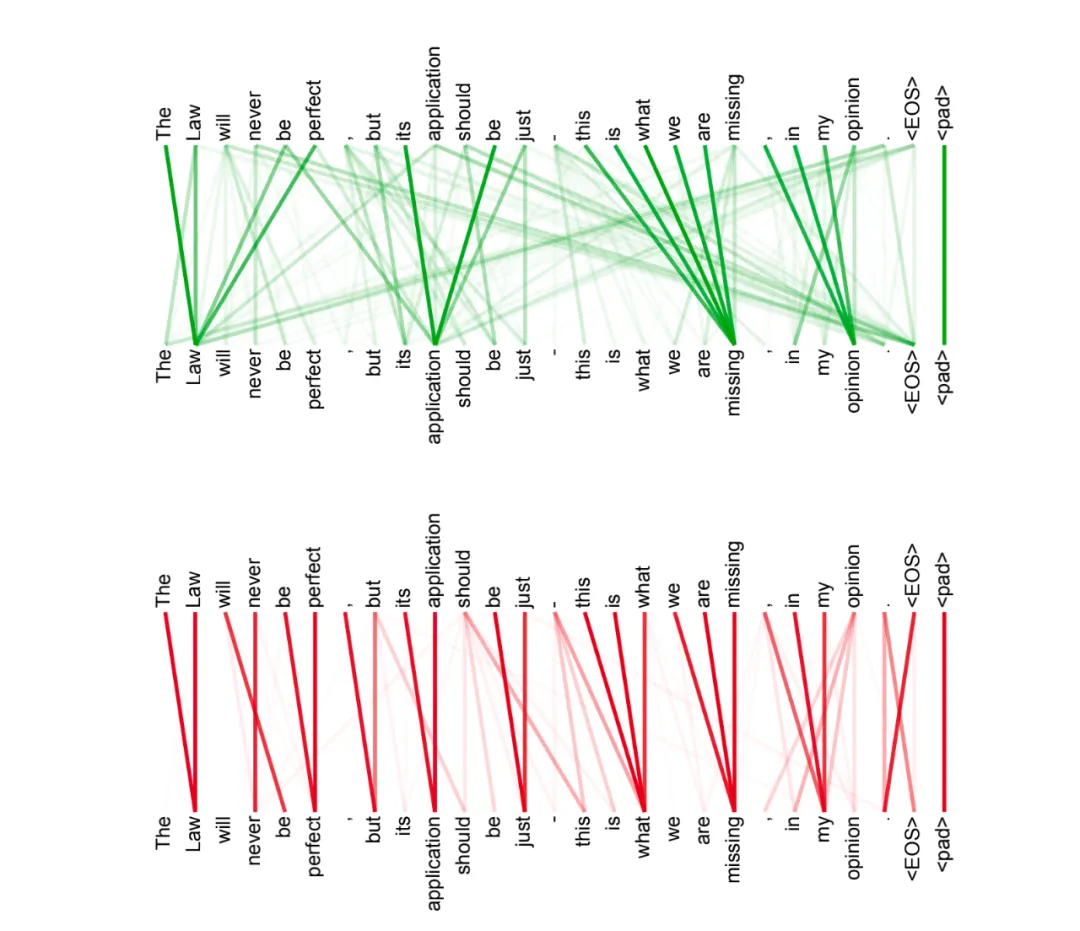
图中,线条越粗表示attention的权重越大,可以看出,两个头关注的地方不一样,绿色图说明该头更关注全局信息,红色图说明该头更关注局部信息。
2.3.2 Add&Norm结构
从结构图不难看出网络加入了residual结构,所以add很好理解,就是输入张量与输出张量相加的操作。
Norm操作与CV常用的BN不太一样,这里采用NLP领域较常用的LN(Layer Norm)。(关于BN、LN、IN、GN的计算方式可以参考《GN-Group Normalization》)
还要多说一下的是,文章中共Add&Norm结构是先相加再进行Norm操作。
2.3.3 Feed Forward结构
该结构很简单,由两个全连接(或者kernel size为1的卷积)和一个ReLU激活单元组成。
Feed Forward结构用公式表示如下
2.4 Decoder结构
Decoder同样也包含了N个重复的block结构,文章N=6。下面来拆解一个每个块的具体结构。
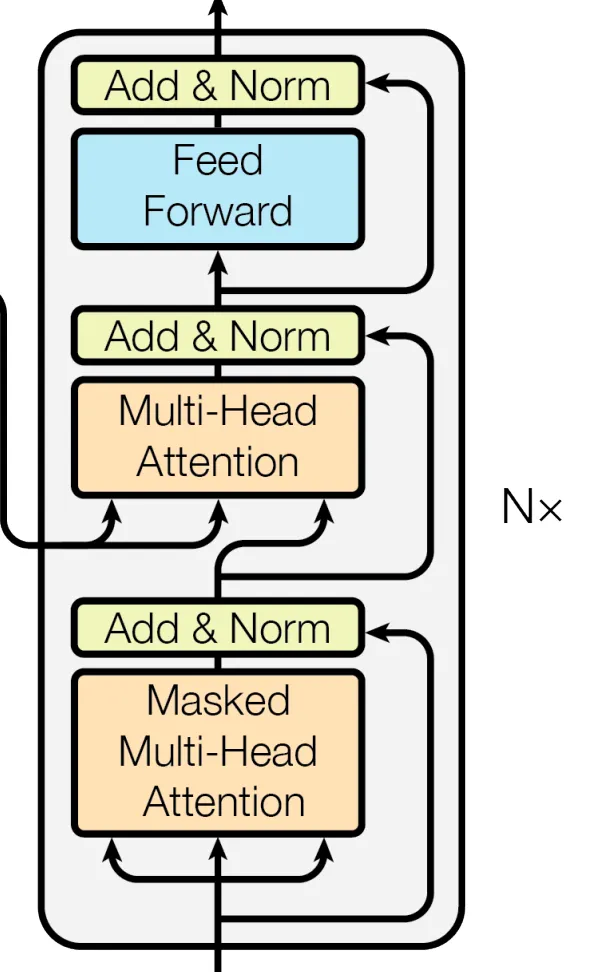
2.4.1 Masked Multi-Head Attention
从名字可以看出它比2.3.1部分介绍的Multi-Head Attention结构多一个masked,其实它的基本结构如下图所示
可以看出这就是Scaled Dot-Product Attention,只是这里mask是启用的状态。
这里先从维度角度考虑mask是怎么工作的,然后再解释为什么要加这个mask操作。
mask工作方式
为了方便解释,先不考虑多batch和多head情况。
可以假设Q\K的维度皆为,V的维度为。
那么在进行mask操作前,经过MatMul和Scale后得到的张量维度为 。
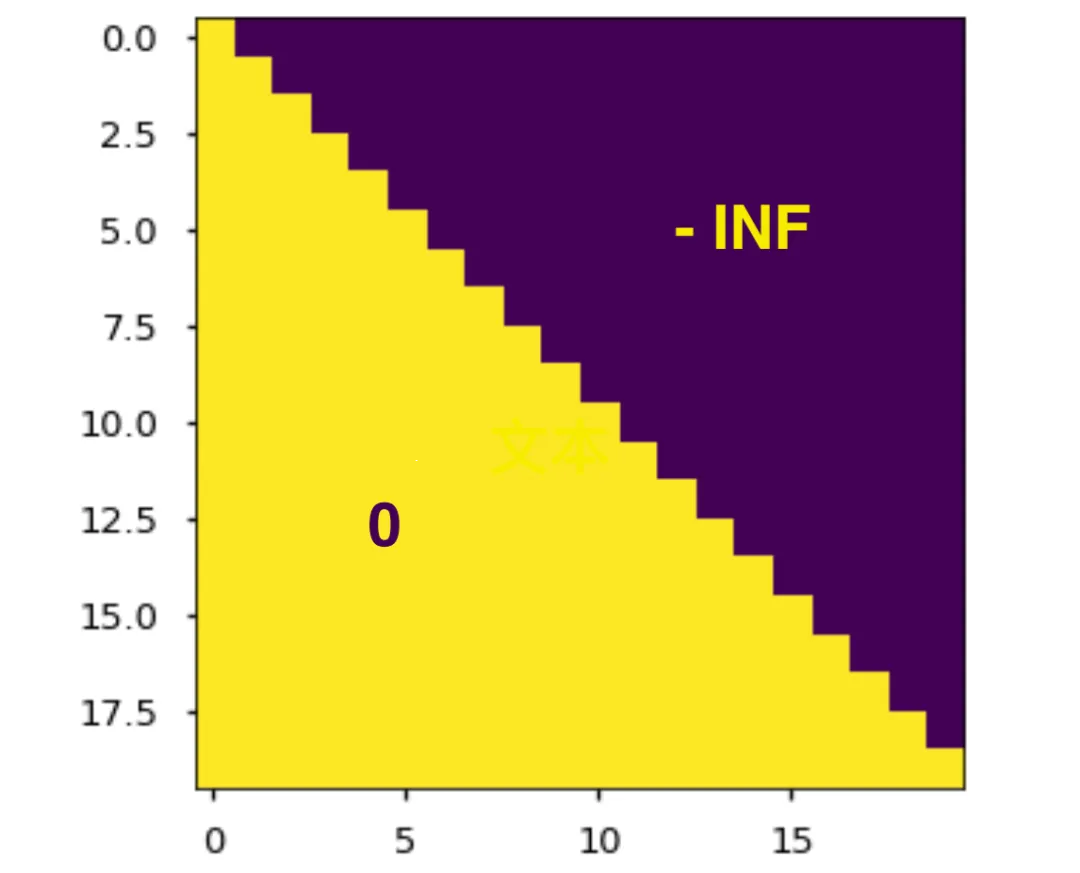
现在有一个提前计算好的mask为,M是一个上三角为-inf,下三角为0的方阵。如下图所示(图中假设L=5)。
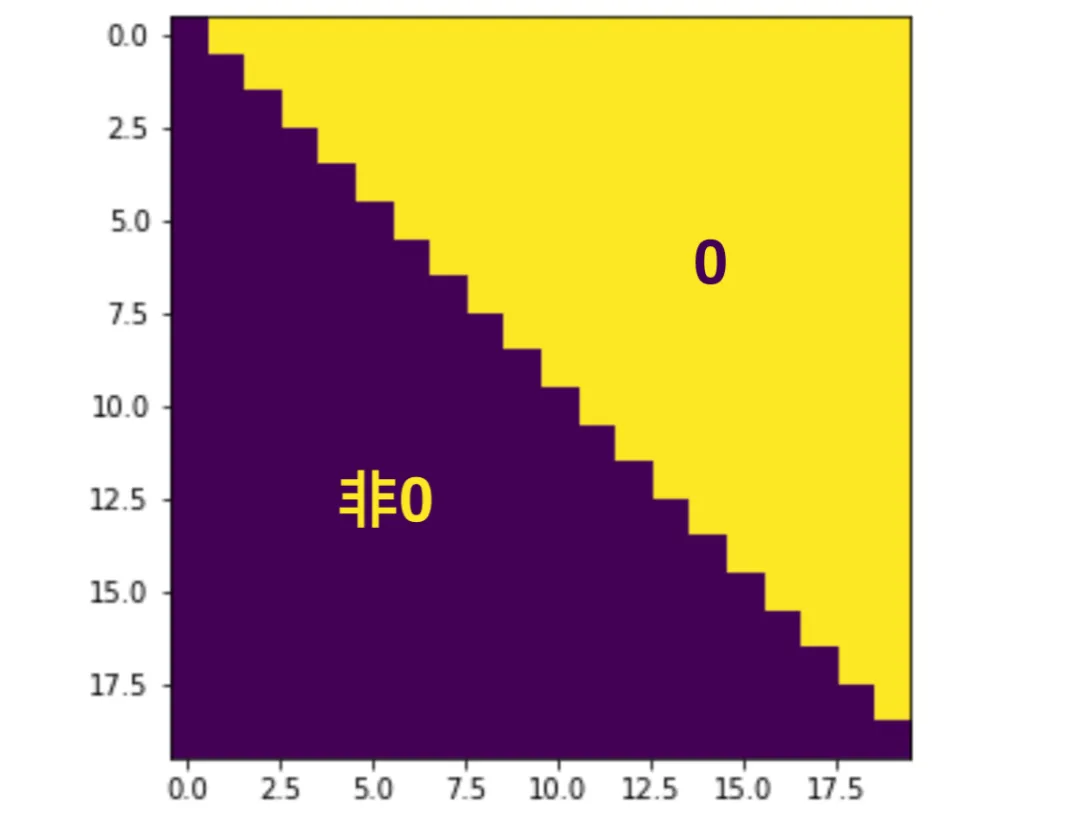
的结果如下图所示(图中假设L=5)
注意:下图中的非0区域的值不一定是一样的,这里为了方便显示画成了一样的颜色
现在Scaled Dot-Product Attention的公式如下所示
 从上述运算可以看出mask的目的是为了让V与attention权重计算attention操作时只考虑当前元素以前的所有元素,而忽略之后元素的影响。即V的维度为,那么第i个元素只考虑0-i元素来得出attention的结果。
从上述运算可以看出mask的目的是为了让V与attention权重计算attention操作时只考虑当前元素以前的所有元素,而忽略之后元素的影响。即V的维度为,那么第i个元素只考虑0-i元素来得出attention的结果。
mask操作的作用
在解释mask作用之前,我们先解释一个概念叫teacher forcing。
teacher forcing这个操作方式经常在训练序列任务时被用到,它的含义是在训练一个序列预测模型时,模型的输入是ground truth。
举例来说,对于"I Love China -> 我爱中国"这个翻译任务来说,测试阶段,Encoder会将输入英文编译为feature,Decoder解码时首先会收到一个BOS(Begin Of Sentence)标识,模型输出"我",然后将"我"作为decoder的输入,输出"爱",重复这个步骤直到输出EOS(End Of Sentence)标志。
但是为了能快速的训练一个效果好的网络,在训练时,不管decoder输出是什么,它的输入都是ground truth。例如,网络在收到BOS后,输出的是"你",那么下一步的网络输入依然还是使用gt中的"我"。这种训练方式称为teacher forcing。如下图所示:
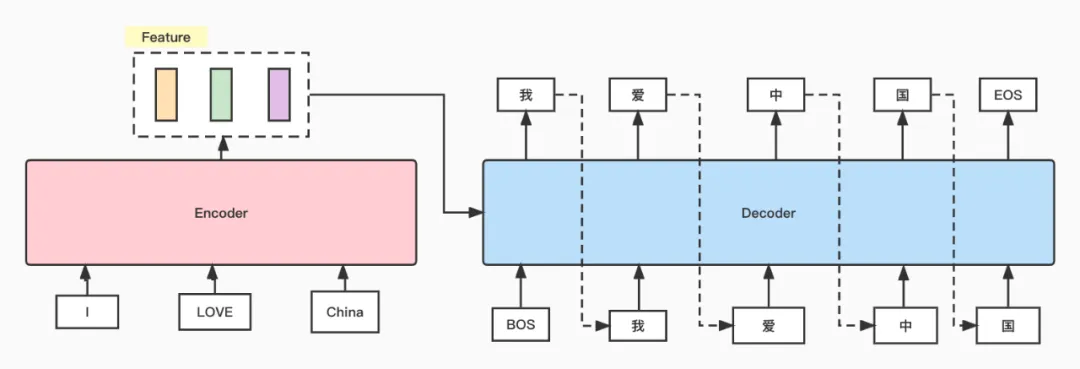
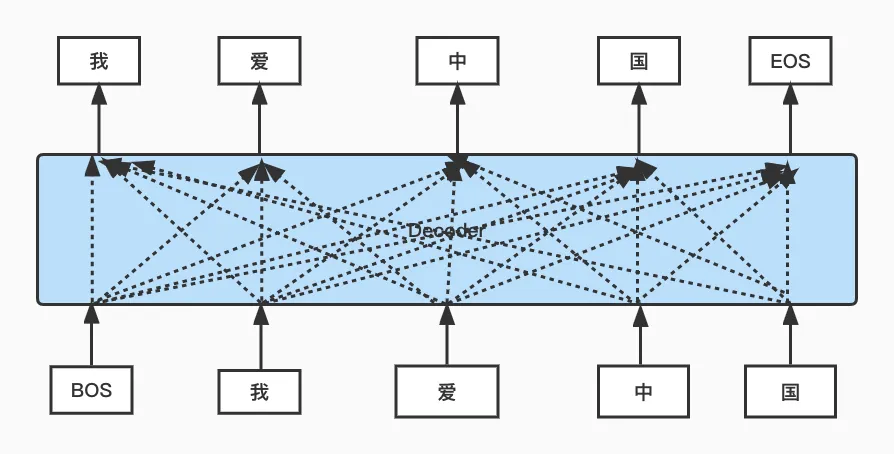
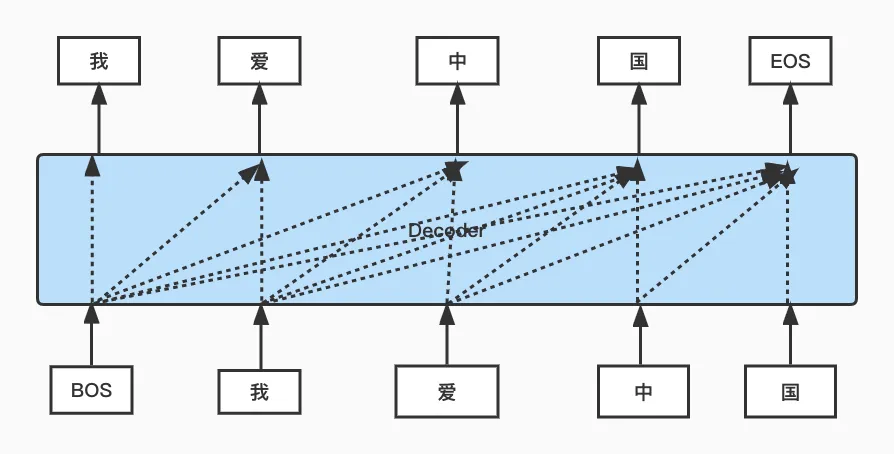
我们看下面两张图,第一张是没有mask操作时的示例图,第二张是有mask操作时的示例图。可以看到,按照teacher forcing的训练方式来训练Transformer,如果没有mask操作,模型在预测"我"这个词时,就会利用到"我爱中国"所有文字的信息,这不合理。所以需要加入mask,使得网络只能利用部分已知的信息来模拟推断阶段的流程。
2.4.2 Multi-Head Attention(decoder)
decoder中的Multi-Head Attention内部结构与encoder是一模一样的,只是输入中的Q为2.4.1部分提到的Masked Multi-Head Attention的输出,输入中的K与V则都是encoder模块的输出。
下面用一张图来展示encoder和decoder之间的信息传递关

decoder中Add&Norm和Feed Forward结构都与encoder一模一样了。
2.5 其它说明
从图中看出encoder和decoder中每个block的输入都是一个张量,但是输入给attention确实Q\K\V三个张量?
对于block来说,Q=K=V=输入张量
推断阶段,解码可以并行吗?
不可以,上面说的并行是采用了teacher forcing+mask的操作,在训练时可以并行计算。但是推断时的解码过程同RNN,都是通过auto-regression方式获得结果的。(当然也有non auto-regression方面的研究,就是一次估计出最终结果。
参考: