

BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Bert 取名来自 Bidirectional Encoder Representations from Transformers,大致可以了解到他采用的是双向的 Transformer 的 Encoder 结构。
因此,阅读论文时我们可以关注下 Bert 模型的两个点:
利用 Encoder 完成预训练后如何配合下游任务?
预训练过程的双向是类似 ELMo 的双向吗?如果不是的话,怎么去防止数据泄漏?
1. Introduction
通过预训练语言模型可以显著提高 NLP 下游任务,包括 NER、QA、知识推理等。目前的预训练有两种策略:feature-based 和 fine-tuning,对应着我们之前介绍过两个预训练模型:ELMo 和 GPT。基于 feature-based 的 ELMo 是针对指定任务进行预训练;而基于 fine-tuning 的 GPT 设计的是一个通用架构,并针对下游任务进行微调,两方法都是使用单向的语言模型来学习一般的语言表示。
但是谷歌的同学认为,预训练的潜力远远不应该只有这些,特别是对于 fine-tuning 来说。限制模型潜力的主要原因在于现有模型使用的都是单向的语言模型,无法充分了解到单词所在的上下文结构(试想:我们想了解一个单词的含义,其实是会结合上下文来判断,而不是只结合单词的上文)。
针对这一痛点:谷歌的同学提出了新的预训练方法 BERT。BERT 受完形填空(cloze task)的启发,通过使用 “Masked Language Model” 的预训练目标来缓解单向语言模型的约束。
首先 “Masked Language Model” 会随机屏蔽(masked)一些单词,然后让模型根据上下文来预测被遮挡的单词。与 ELMo 不同的是,BERT 是真正的结合上下文进行训练,而 ELMo 只是左向和右向分别训练。
除了 “Masked Language Model” 外,谷歌的同学还提出了 “next sentence prediction” 的任务预训练文本对。将 token-level 提升到 sentence-level,以应用不同种类的下游任务。
我们来看下 Bert 的具体内容。
2. BERT
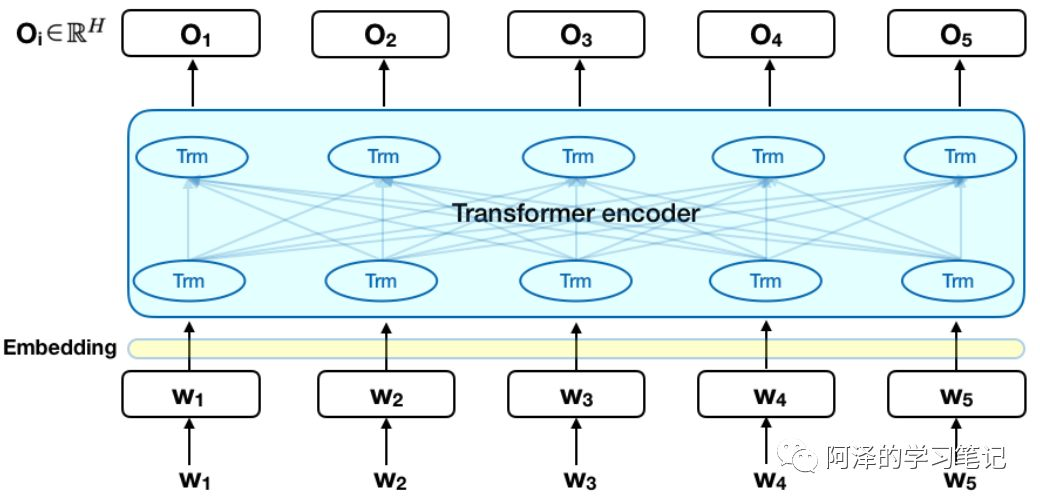
BERT 和之前的模型类似都采用两阶段的步骤:pre-training 和 fine-tuning。pre-training 阶段,BERT 在未标记的数据上进行无监督学习;而 fine-tuning 阶段,BERT 首先利用预训练得到的参数初始化模型,然后利用下游任务标记好的数据进行有监督学习,并对所有参数进行微调。所有下游任务都有单独的 fine-tuning 模型,即使是使用同样的预训练参数。下图是对 BERT 的一个概览:

2.1 Model Architecture
先来看下模型的架构:
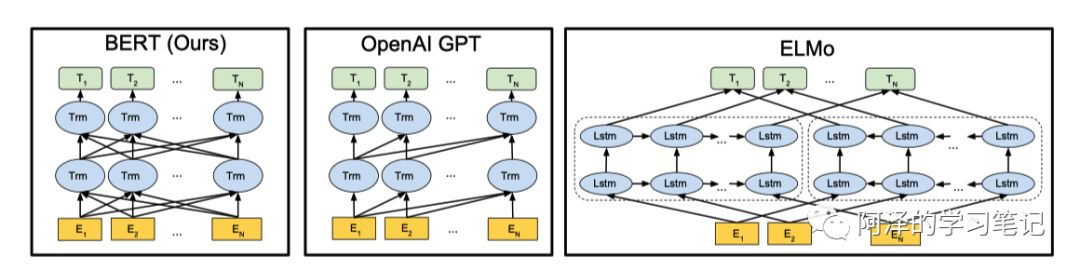
BERT 是由多层双向的 Transformer Encoder 结构组成,区别于 GPT 的单向的 Transformer Decoder 架构。
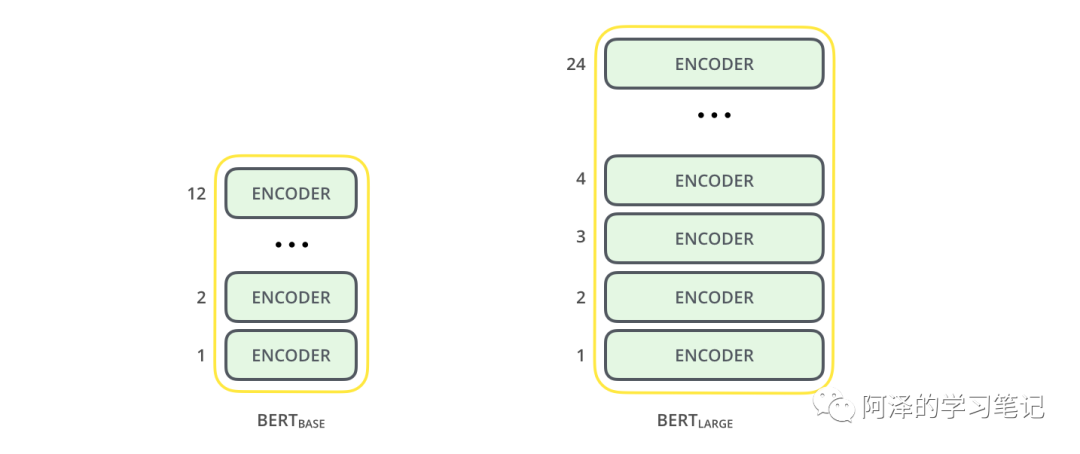
谷歌的同学在论文中提供了两个不同规模的 BERT:BERT Base 和 BERT Large。前者有 12 个隐藏层,768 个隐单元,每个Multi-head Attention 中有 12 个 Attention,共 1.1 亿参数,主要是为了与 OpenAI 比较性能;而后者有 24 个隐藏层,1024 个隐单元,每个 Multi-head Attention 中有 16 个Attention,共 3.4 亿参数,主要是用来秀肌肉的。
2.2 Input/Output
为了能应对下游任务,BERT 给出了 sentence-level 级别的 Representation,包括句子和句子对。
在 BERT 中 sequence 并不一定是一个句子,也有可能是任意的一段连续的文本;而句子对主要是因为类似 QA 问题。
我们来看下 BERT 的输入:
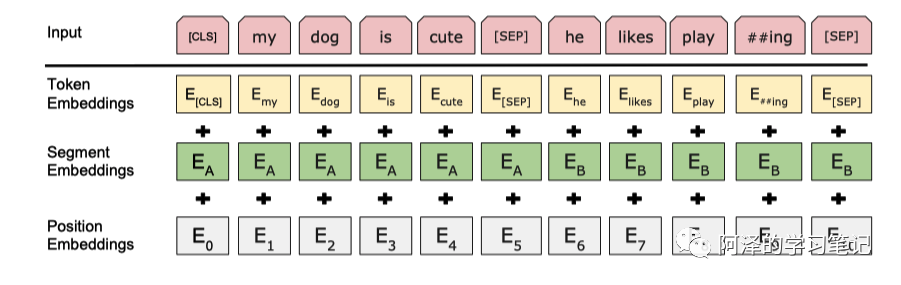
分为三块:Token Embeddings、Segment Embeddings 和 Position Embeddings。
Token Embeddings 采用的 WordPiece Embedding,共有 30000 个 token。每个 sequence 会以一个特殊的 classification token [CLS] 开始,同时这也会作为分类任务的输出;句子间会以 special token [SEP] 进行分割。
WordPiece Embedding:n-gram 字符级 Embedding,采用 BPE 双字节编码,可以将单词拆分,比如 “loved” “loving” ”loves“ 会拆分成 “lov”,“ed”,“ing”,“es”。 ”
Segment Embedding 也可以用来分割句子,但主要用来区分句子对。Embedding A 和 Embedding B 分别代表左右句子,如果是普通的句子就直接用 Embedding A。
Position Embedding 是用来给单词定位的,直接使用 one-hot 编码。
BERT 最终的 input 是三种不同的 Embedding 直接相加。
2.3 Pre-training
BERT 采用两种非监督任务来进行预训练,一个是 token-level 级别的 Masked LM,一个是 sentence-level 级别的 Next Sentence Prediction。两个任务同时训练,所以 BERT 的损失函数是两个任务的损失函数相加。
2.3.1 Masked LM
我们知道语言模型只能是单向的,即从左到右或者从右到左,而使用双向的话会导致数据泄漏问题,即模型可以间接看到要预测的单词。这也是为什么 ELMo 要采用两个独立的双向模型的原因。
为了解决这个问题,谷歌的同学提出了 Masked LM 的概念:随机屏蔽一些 token 并通过上下文预测这些 token。这种况下就解决了双向模型和数据泄漏的问题。在具体实验过程中,BERT 会随机屏蔽每个序列中的 15% 的 token,并用 [MASK] token 来代替。
但这样会带来一个新的问题:[MASK] token 不会出现在下游任务中。为了缓解这种情况,谷歌的同学采用以下三种方式来代替 [MASK] token:
80% 的 [MASK] token 会继续保持 [MASK];
10% 的 [MASK] token 会被随机的一个单词取代;
10% 的 [MASK] token 会保持原单词不变(但是还是要预测)。
最终 Masked ML 的损失函数是只由被 [MASK] 的部分来计算。
这样做的目的主要是为了告诉模型 [MASK] 是噪声,以此来忽略标记的影响。
2.3.2 Next Sentence Prediction
部分下游任务如问答(QA)、语言推理等都是建立在句子对的基础上的,而语言模型只能捕捉 token-level 级别的关系,捕捉不了 sentence-level 级别的关系。
为了解决这个问题,谷歌的同学训练了一个 sentence-level 的分类任务。具体来说,假设有 A B 两个句对,在训练过程 50% 的训练样本 A 下句接的是 B 作为正例;而剩下 50% 的训练样本 A 下句接的是随机一个句子作为负例。并且通过 classification token 连接 Softmax 输出最后的预测概率。

虽然很简单,但是在实际效果是非常好的。
2.4 Fine-tuning
预训练好后我们看下 BERT 的 Fine-tuning 是怎么实现的。
由于预训练的 Transformer 已经完成了句子和句子对的 Representation,所以 BERT 的 Fine-tuning 非常简单。
针对不同的下游任务,我们可以将具体的输入和输出是适配到 BERT 中,并且采用端到端的训练去微调模型参数。如下图所示:
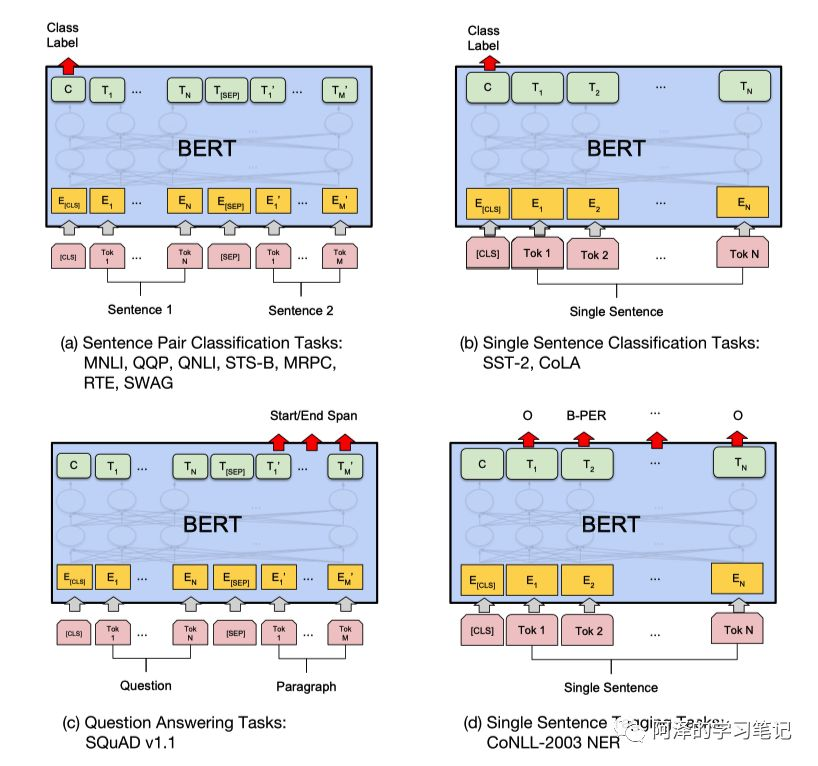
a b 是 sentence-level 级别的任务,类似句子分类,情感分析等等,输入句子或句子对,在 [CLS] 位置接入 Softmax 输出 Label;
c 是 token-level 级别的任务,比如 QA 问题,输入问题和段落,在 Paragraph 对应输出的 hidden vector 后接上两个 Softmax 层,分别训练出 Span 的 Start index 和 End index(连续的 Span)作为 Question 的答案;
d 也是 token-level 级别的任务,比如命名实体识别问题,接上 Softmax 层即可输出具体的分类。
3. Experience
简单看下实验部分。
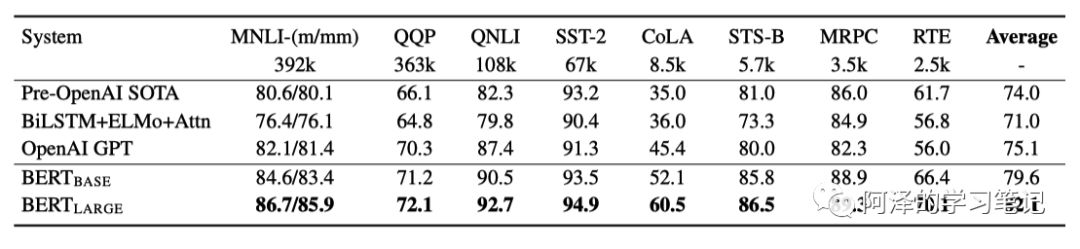
下图是与不同模型的对比:
下图是 Masked LM 与 单向的 LM 的实验对比:

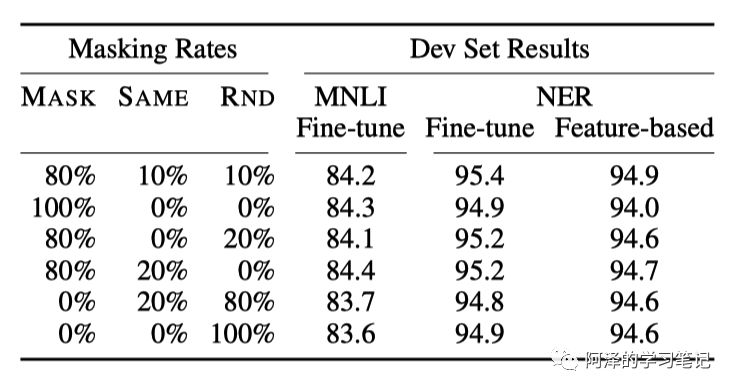
下图为不同 Mask 策略下的效果:
最后放一张图,简单看下 BERT、GPT 和 ELMo 三者的对比:
4. Conclusion
总结:BERT 采用 Pre-training 和 Fine-tuning 两阶段训练任务,在 Pre-training 阶段使用多层双向 Transformer 进行训练,并采用 Masked LM 和 Next Sentence Prediction 两种训练任务解决 token-level 和 sentence-level 的问题,为下游任务提供了一个通用的模型框架;在 Fine-tuning 阶段会针对具体 NLP 任务进行微调以适应不同种类的任务需求,并通过端到端的训练更新参数从而得到最终的模型。
BERT 是 NLP 领域中一个里程碑式的工作,并对后续 NLP 的研究工作产生了深远影响。
自此 BERT 就介绍完了。

5. Reference
《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
《The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)》
《BERT – State of the Art Language Model for NLP》