NCCL详解
linux查询nccl版本号:
python -c “import torch; print(torch.cuda.nccl.version())”NCCL是一个实现多GPU的collective communication通信库,做了很多的优化,以在PCle,Nvlink,InfiniBand实现较高的通信速度。
下面分别从以下几个方面来介绍NCCL的特点,包括基本的communication primitive、ring-base collectives、NCCL在单机多卡上以及多机多卡实现、最后分享实际使用NCCL的一些经验。
1.communication primitive
并行任务的通信一般分为point-to-point communication和Collective communication。P2P这种通信方式只会涉及到一个sender和一个receiver,实现起来比较简单。第二种的Collective communication包含了多个sender和多个receiver,一般的通信原语包括broadcast,gather,all-gather,scatter,reduce,all-reduce,reduce-scatter,all-to-all等。简单的介绍几个常用的操作:
Reduce:从多个sender那里接收数据,最终combine到一个节点上面。
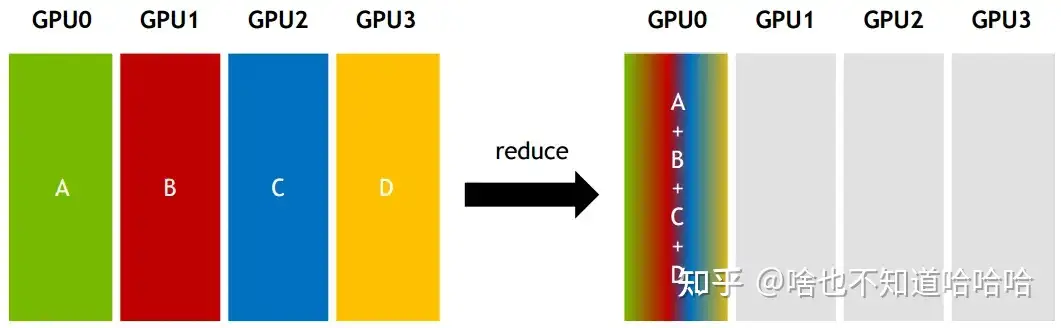
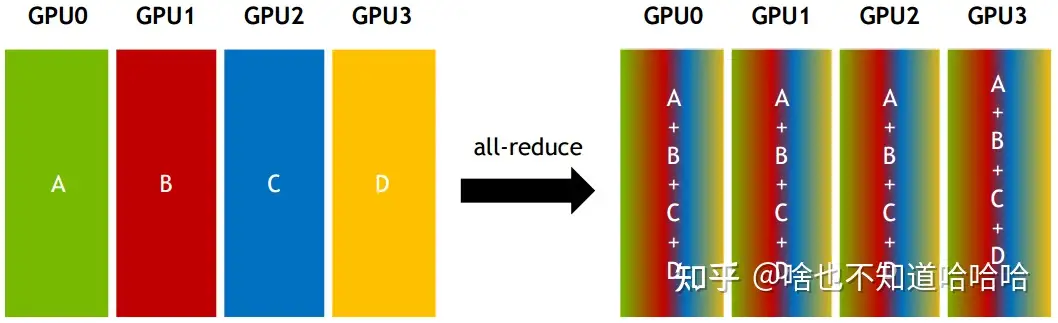
All-reduce:从多个sender那里接收数据,最终combine到每一个节点上面。
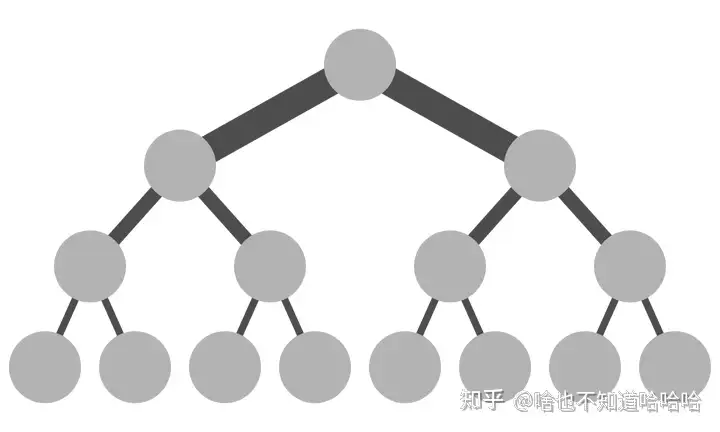
而传统的Collective communication(集体通信)假设通信节点组成的topology是一颗fat tree(多层次的树状网络,其中存在多个层级的交换节点,能够提供大带宽和低延迟的通信),如下图所示,这样通信效率最高。但实际的通信topology可能比较复杂,并不是一个fat tree。因此一般用ring-based Collective communication(环形)。
2.ring-base collectives
将所有的通信节点组成首尾相接的环,数据在环上面进行传输。以broadcast为例子,假设有4个GPU,GPU0为sender将信息发送给剩下的GPU,按照环的方式依次传输,GPU0-->GPU1-->GPU2-->GPU3,若数据量为N,带宽为B,整个传输时间为(K-1)N/B。时间随着节点数线性增长,不是很高效。
解释一下上面的计算过程:
传输时间公式: 先看一下传输时间的公式:传输时间 = 数据量 / 带宽。在这里,数据量为 N,带宽为 B,所以传输时间为 N / B。
环形传输的时间: 由于数据按照环形依次传输,假设有 K 个 GPU(包括发送者 GPU0),那么数据需要经过 K-1 个节点才能到达最终的目的地。因此,整个传输时间为(K-1)* (N / B)。其中,K-1 是因为第一个 GPU0 作为发送者,不需要传输时间。
时间随着节点数线性增长:由于每增加一个 GPU,需要额外的传输时间来经过一个新的节点。因此,当 GPU 数量增加时,传输时间是线性增长的,即时间与节点数成正比。
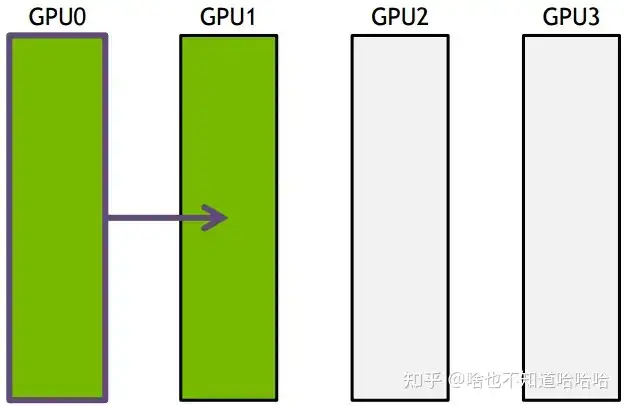
下面把要传输的数据分成S份,每次传入N/S的数据量,传输过程如下所示:
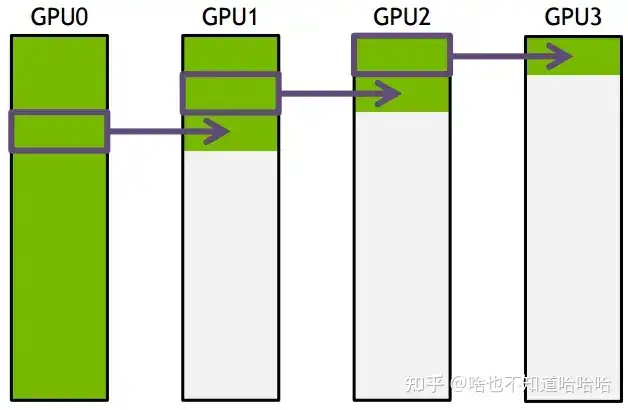
GPU1接收到GPU0的一份数据后,也接着传到环的下个节点,这样以此类推,最后花的时间为
S*(N/S/B) + (k-2)*(N/S/B) = N(S+K-2)/(SB) --> N/B,条件是S远大于K,即数据的份数大于节点数,这个很容易满足。所以通信时间不随节点数的增加而增加,只和数据总量以及带宽有关。其它通信操作比如reduce、gather以此类推。
那么在以GPU为通信节点的场景下,怎么构建通信环呢?如下图所示:
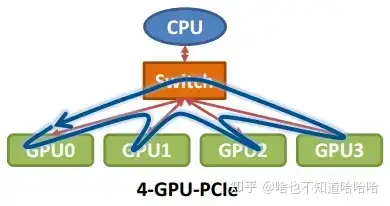
单机4卡通过同一个PCIe switch挂载在一棵CPU的场景:
对于这个PCle switch:
PCIe switch 是指 PCI Express(PCIe)总线上的交换机设备。PCIe 是一种计算机总线标准,用于连接计算机内部的各种设备,如显卡、网络适配器、存储控制器等。
PCIe switch 的作用类似于网络中的交换机,它允许多个 PCIe 设备同时连接到一个主机,实现设备之间的通信和数据传输。
总的来说:PCIe switch 是用于连接和管理多个 PCIe 设备的设备,它在计算机系统中起到类似于网络交换机的作用,实现了设备之间的高速数据传输和通信。
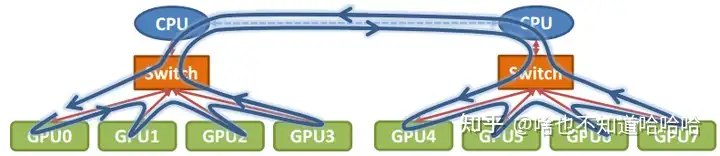
单机8卡通过两个CPU下不同的PCIe switch挂载的场景:
3.NCCL的实现
NCCL实现成CUDA C++ kernels,包含3种primitive operations: Copy,Reduce,ReduceAndCopy。目前NCCL 1.0版本只支持单机多卡,卡之间通过PCIe、NVlink、GPU Direct P2P来通信。NCCL 2.0会支持多机多卡,多机间通过Sockets (Ethernet)或者InfiniBand with GPU Direct RDMA通信。
3.1NCCL:是由 NVIDIA 开发的一种用于实现并行计算中通信操作的库。它专门用于在 GPU 上进行高效的数据通信和集体操作。
3.2CUDA C++ kernels: CUDA 是 NVIDIA 开发的一种并行计算平台和编程模型,允许开发人员使用 C++ 语言编写并行计算任务,并在 NVIDIA GPU 上执行。CUDA C++ kernels 是在 GPU 上执行的 CUDA C++ 程序的核心部分,用于执行计算任务。
3.3Primitive operations(基本操作): 在计算中,原语操作指的是一组最基本的操作或功能,它们通常是构建更复杂的算法或功能的基础。在 NCCL 中,原语操作包括 Copy(复制)、Reduce(归约)和 ReduceAndCopy(归约并复制)等,用于实现并行计算中的数据通信和集合操作。
3.4PCIe(Peripheral Component Interconnect Express): PCIe 是一种计算机总线标准,用于连接计算机内部的各种设备,如显卡、网络适配器、存储控制器等。在单机多卡的场景中,NCCL 使用 PCIe 来实现 GPU 卡之间的通信。
3.5NVlink: NVLink 是 NVIDIA 开发的一种高速互连技术,用于连接 NVIDIA GPU 和其他 GPU、CPU 或其他设备。它提供比 PCIe 更高的带宽和更低的延迟,适用于高性能计算和数据中心应用。
3.6GPU Direct P2P:GPU Direct Peer-to-Peer 是一种技术,允许两个 GPU 直接在没有 CPU 参与的情况下进行数据传输,从而提高数据传输效率和性能。
3.7Sockets (Ethernet): Sockets 是一种用于网络通信的 API(应用程序接口),通常用于在网络上建立连接和进行数据传输。在多机多卡的场景中,NCCL 2.0 可以使用 Sockets(Ethernet)来实现跨机器的 GPU 通信。
下图所示,单机内多卡通过PCIe以及CPU socket通信,多机通过InfiniBand通信。
CPU socket: CPU 插槽是计算机主板上的插槽,用于安装 CPU。一台计算机可以有多个 CPU 插槽,每个插槽可以安装一个 CPU。在这种情况下,多个 GPU 卡通过连接到不同 CPU 插槽的主机系统中的 CPU 进行通信。
多机通过 InfiniBand 通信:多机意味着计算任务分布在多台计算机之间,即不同的设备之间需要进行通信。InfiniBand: 是一种高性能互连技术,用于连接计算机集群中的节点。它提供了低延迟和高带宽的数据传输,适用于需要大规模计算和数据传输的应用场景。在这种情况下,多个计算机之间通过 InfiniBand 网络进行通信和数据传输。
InfiniBand: 在多个计算节点之间进行数据通讯时,如果系统使用 InfiniBand 互连,通常会使用 InfiniBand 网络技术和相应的通信库(如 MPI、RDMA)来实现高性能的数据传输和通讯。这种方式可以实现低延迟、高带宽的数据传输,适用于需要大规模并行计算和数据处理的应用场景。
Sockets: 如果系统使用基于 Ethernet 的通信网络,通常会使用 Sockets 编程接口和 TCP/IP 或 UDP 协议来进行数据通讯。这种方式提供了通用的网络通信功能,但可能无法提供与 InfiniBand 相当的性能和效率,特别是在大规模并行计算和高性能计算环境中。
在分布式训练中,多个计算节点之间通过哪几种方式进行数据传输呢?
以太网 (Ethernet): 对于大多数分布式系统,以太网是最常见的通信方式。它适用于不同规模的网络,从小型实验室设置到大型数据中心。以太网的传输速度可以从千兆位每秒(Gigabit Ethernet, 1GbE)到数十或上百千兆位每秒(10GbE, 40GbE, 100GbE等)不等。尽管以太网在延迟和带宽方面可能不如一些专用网络,但它因其通用性、成本效率和易于配置而广泛使用。
InfiniBand: InfiniBand是一种高性能、低延迟的网络通信技术,常用于超级计算机和数据中心。InfiniBand提供了比传统以太网更高的数据传输速率和更低的延迟,非常适合于要求高性能计算(HPC)和大规模并行计算任务。InfiniBand支持点对点数据传输和RDMA(Remote Direct Memory Access),允许直接从一个节点的内存传输数据到另一个节点的内存,无需CPU介入,从而极大地提高了数据传输效率。
RDMA over Converged Ethernet (RoCE): RoCE是一种网络协议,允许在以太网上实现远程直接内存访问(RDMA)。这意味着它结合了RDMA的高效率和以太网的通用性。RoCE在某些环境中被用作InfiniBand的替代方案,特别是在那些已经部署了高速以太网且不想投资于专用InfiniBand硬件的场景中。
GPU直接通信技术,如NVIDIA的NVLink和AMD的Infinity Fabric:这些技术允许在同一节点内的GPU之间以及不同节点上的GPU之间进行高速数据传输。NVLink和Infinity Fabric提供的带宽远高于PCI Express(PCIe)总线,减少了数据在GPU之间传输的瓶颈,对于加速GPU密集型应用(如深度学习训练)非常有用。
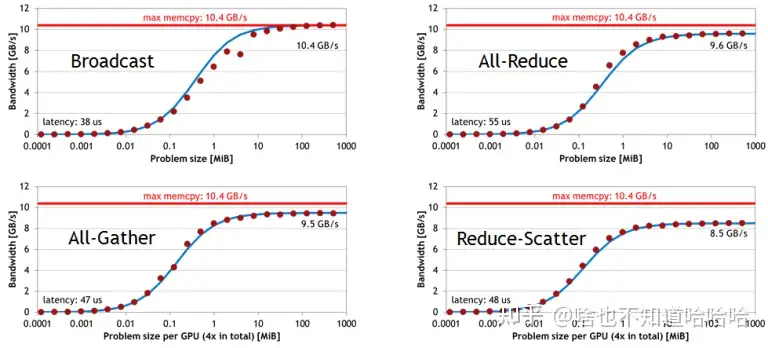
下面是单机 4卡(Maxwel GPU)上各个操作随着通信量增加的带宽速度变化,可以看到带宽上限能达到10GB/s,接近PCIe的带宽。
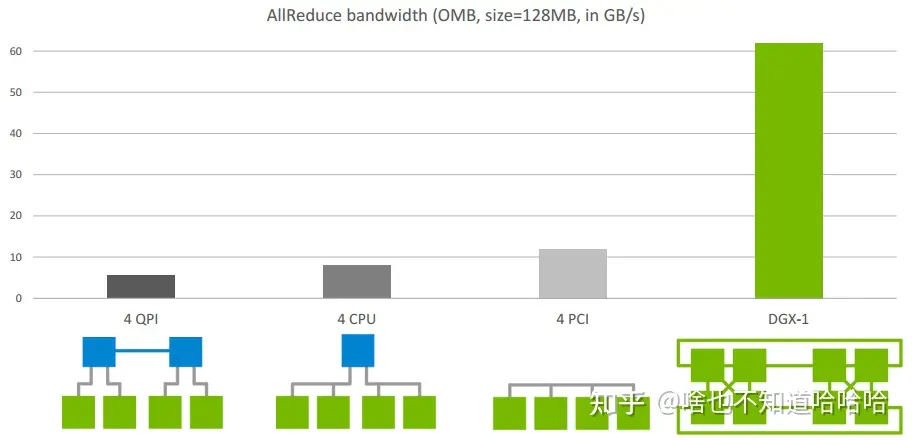
下图是Allreduce在单机不同架构下的速度比较: