

图解大模型训练之:数据并行下篇( DeepSpeed ZeRO,零冗余优化)
一、存储消耗
1.1 存储分类
首先,我们来看在大模型训练的过程中,GPU都需要存什么内容。
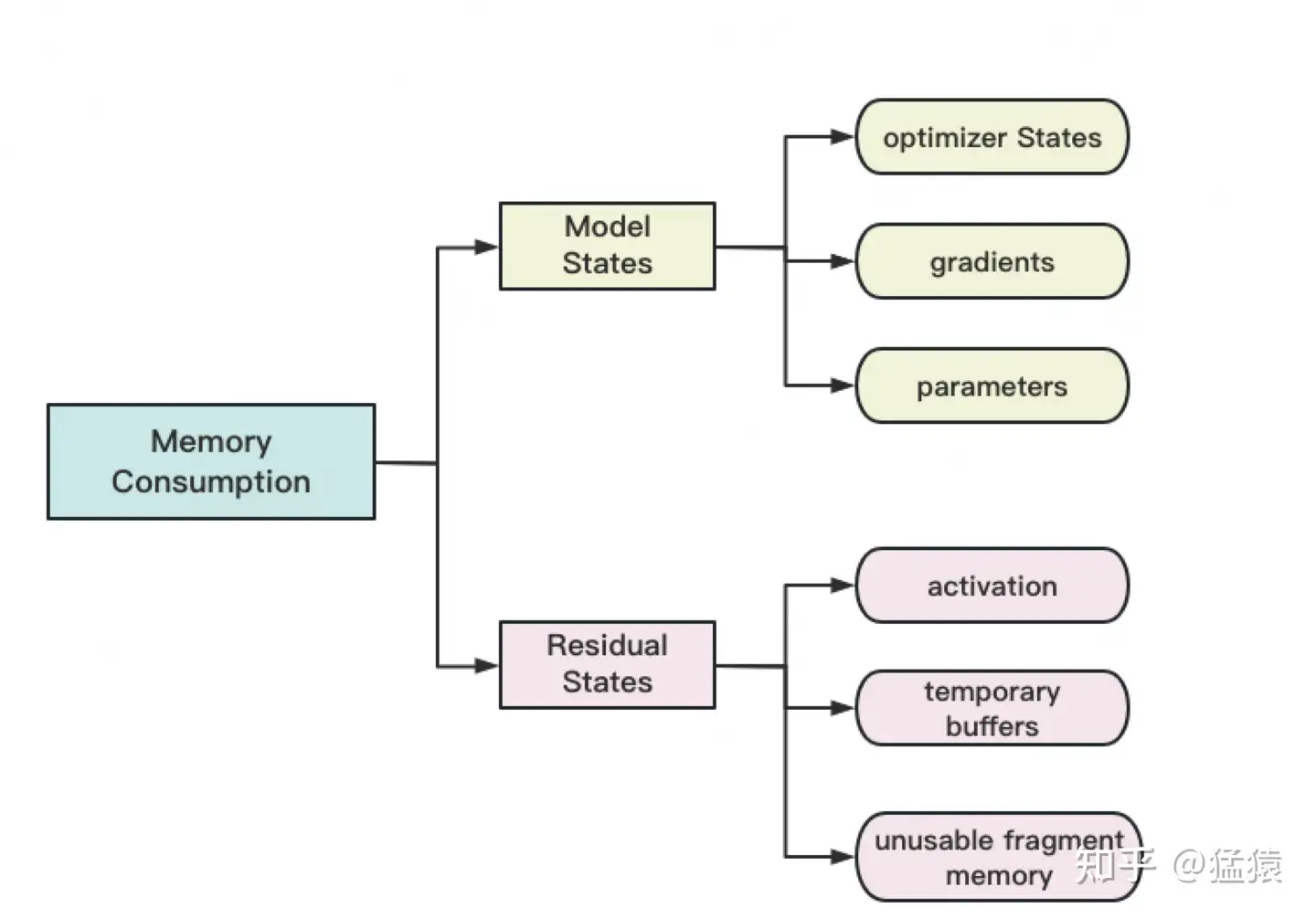
存储主要分为两大块:Model States和Residual States
Model States指和模型本身息息相关的,必须存储的内容,具体包括:
optimizer states:Adam优化算法中的momentum和variance
gradients:模型梯度
parameters:模型参数W
Residual States指并非模型必须的,但在训练过程中会额外产生的内容,具体包括:
activation:激活值。在流水线并行中我们曾详细介绍过。在backward过程中使用链式法则计算梯度时会用到。有了它算梯度会更快,但它不是必须存储的,因为可以通过重新做Forward来算它。
temporary buffers: 临时存储。例如把梯度发送到某块GPU上做加总聚合时产生的存储。
unusable fragment memory:碎片化的存储空间。虽然总存储空间是够的,但是如果取不到连续的存储空间,相关的请求也会被fail掉。对这类空间浪费可以通过内存整理来解决。
1.2 精度混合训练
知道了存储分类,进一步,我们想知道,假设模型的参数W大小是$$$$\Phi $$$$,那么每一类存储具体占了多大的空间呢?
在分析这个问题前,我们需要来了解精度混合训练。
对于模型,我们肯定希望其参数越精准越好,也即我们用fp32(单精度浮点数,存储占4byte)来表示参数W。但是在forward和backward的过程中,fp32的计算开销也是庞大的。那么能否在计算的过程中,引入fp16或bf16(半精度浮点数,存储占2byte),来减轻计算压力呢?于是,混合精度训练就产生了,它的步骤如下图:
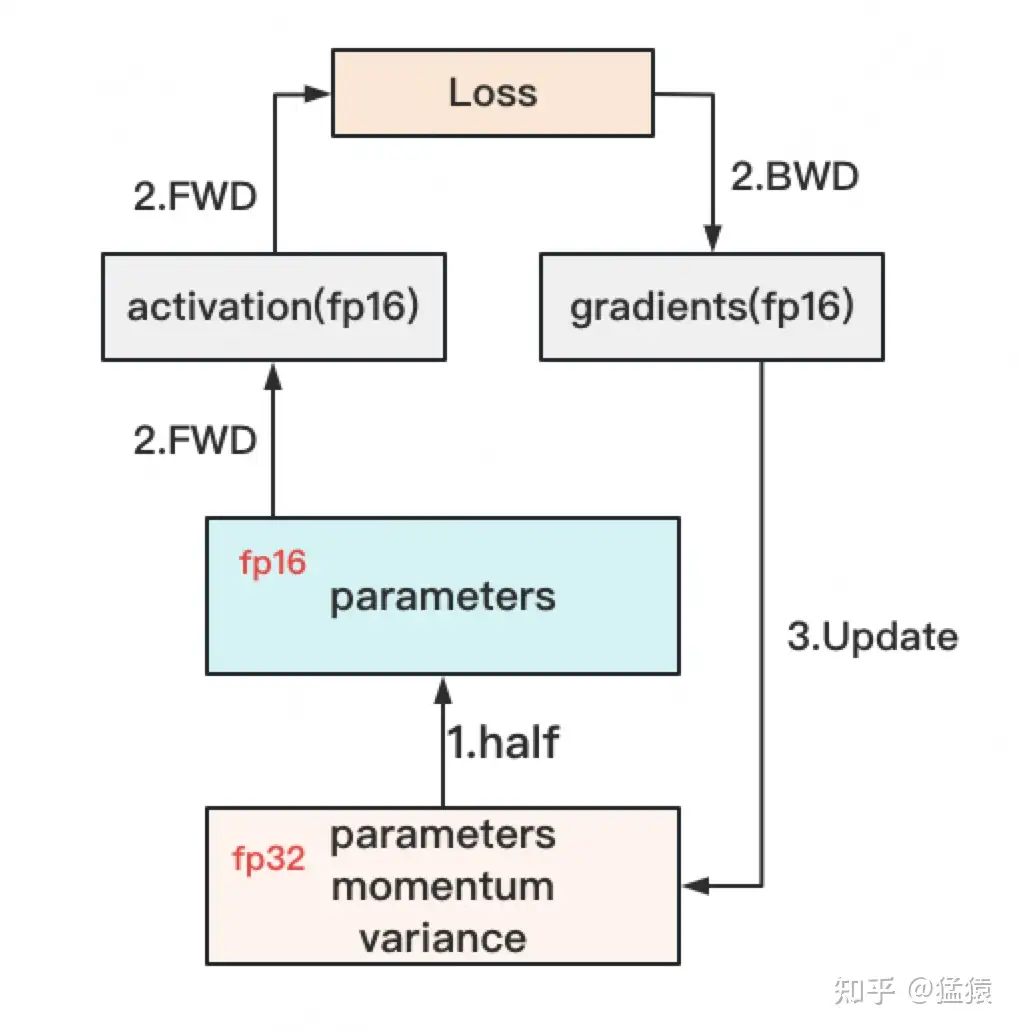
存储一份fp32的parameter,momentum和variance(统称model states)
在forward开始之前,额外开辟一块存储空间,将fp32 parameter减半到fp16 parameter。
正常做forward和backward,在此之间产生的activation和gradients,都用fp16进行存储。
用fp16 gradients去更新fp32下的model states。
当模型收敛后,fp32的parameter就是最终的参数输出。
通过这种方式,混合精度训练在计算开销和模型精度上做了权衡。如果不了解fp32,fp16和bf16的细节也没关系,不影响下文的阅读。只要记住它们所占的存储空间和精度表达上的差异即可。
1.3 存储大小
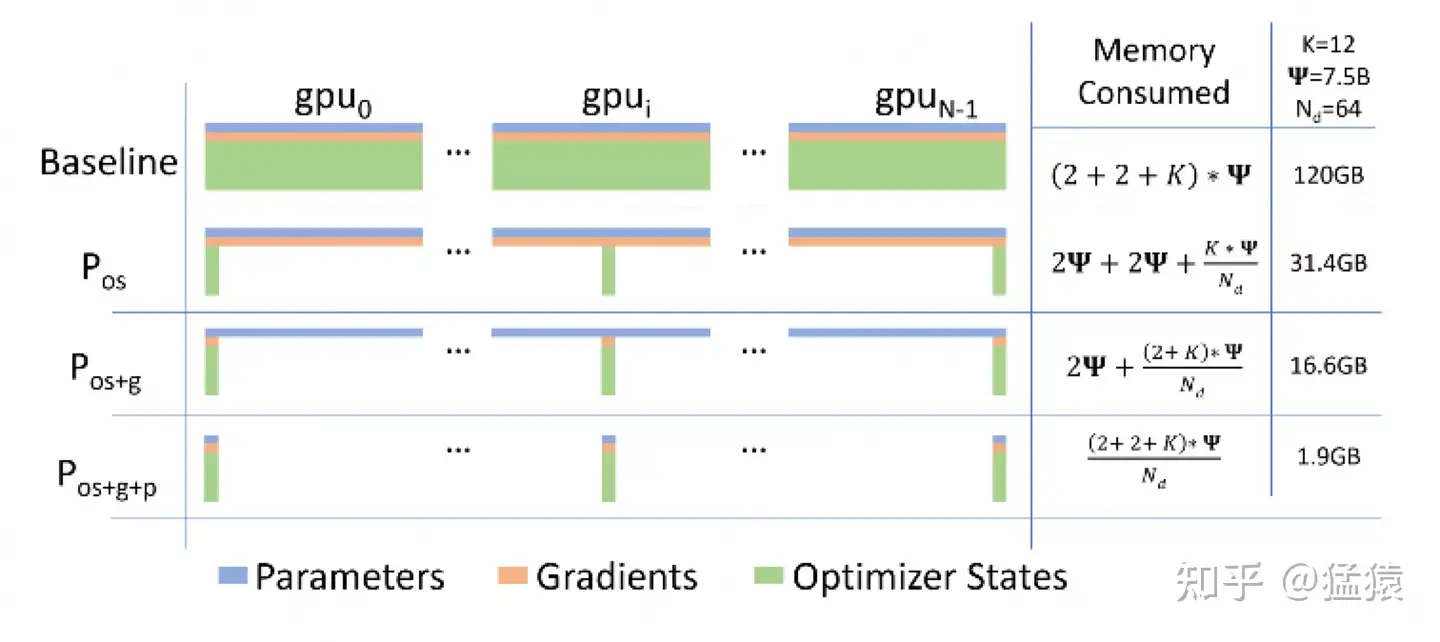
现在,我们可以来计算模型在训练时需要的存储大小了,假设模型的参数W大小是 Φ ,以byte为单位,存储如下:
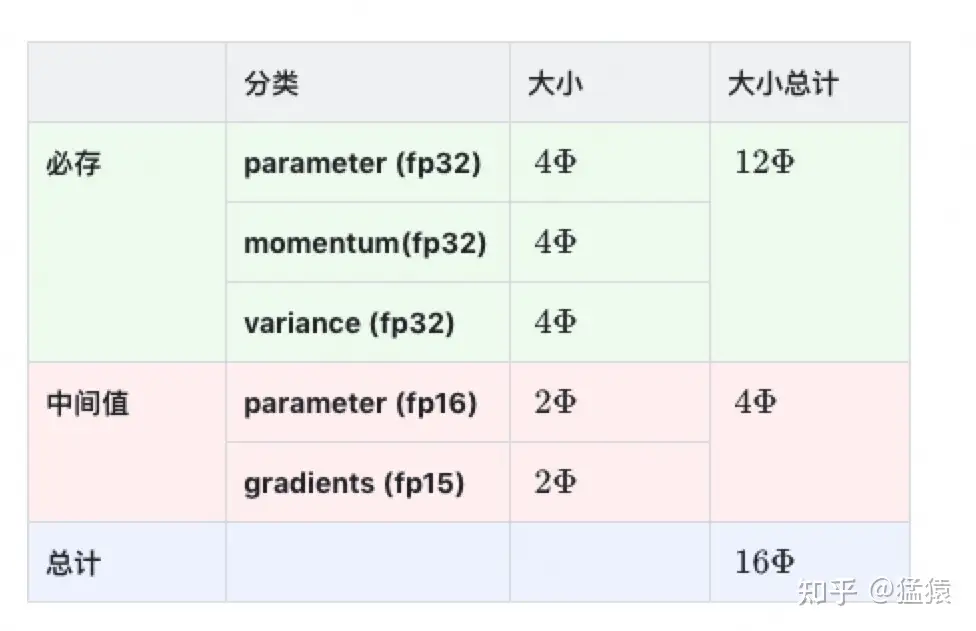
因为采用了Adam优化,所以才会出现momentum和variance,当然你也可以选择别的优化办法。因此这里为了更通用些,记模型必存的数据大小为 𝐾Φ 。因此最终内存开销为: 2Φ+2Φ+𝐾Φ
另外,这里暂不将activation纳入统计范围,原因是:
activation不仅与模型参数相关,还与batch size相关
activation的存储不是必须的。存储activation只是为了在用链式法则做backward的过程中,计算梯度更快一些。但你永远可以通过只保留最初的输入X,重新做forward来得到每一层的activation(虽然实际中并不会这么极端)。
因为activation的这种灵活性,纳入它后不方便衡量系统性能随模型增大的真实变动情况。因此在这里不考虑它,在后面会单开一块说明对activation的优化。
二、ZeRO-DP
知道了什么东西会占存储,以及它们占了多大的存储之后,我们就可以来谈如何优化存储了。
注意到,在整个训练中,有很多states并不会每时每刻都用到,举例来说;
Adam优化下的optimizer states只在最终做update时才用到
数据并行中,gradients只在最后做AllReduce和updates时才用到
参数W只在做forward和backward的那一刻才用到
诸如此类
所以,ZeRO想了一个简单粗暴的办法:如果数据算完即废,等需要的时候,我再想办法从个什么地方拿回来,那不就省了一笔存储空间吗?
沿着这个思路,我们逐一来看ZeRO是如何递进做存储优化的。
(阅读前,如果不熟悉GPU间数据通讯操作,一定要先读猛猿:图解大模型训练之:数据并行上篇(DP, DDP与ZeRO)这一篇)
2.1 𝑃𝑜𝑠:优化状态分割
首先,从 optimizer state开始优化。将optimizer state分成若干份,每块GPU上各自维护一份。这样就减少了相当一部分的显存开销。如下图:
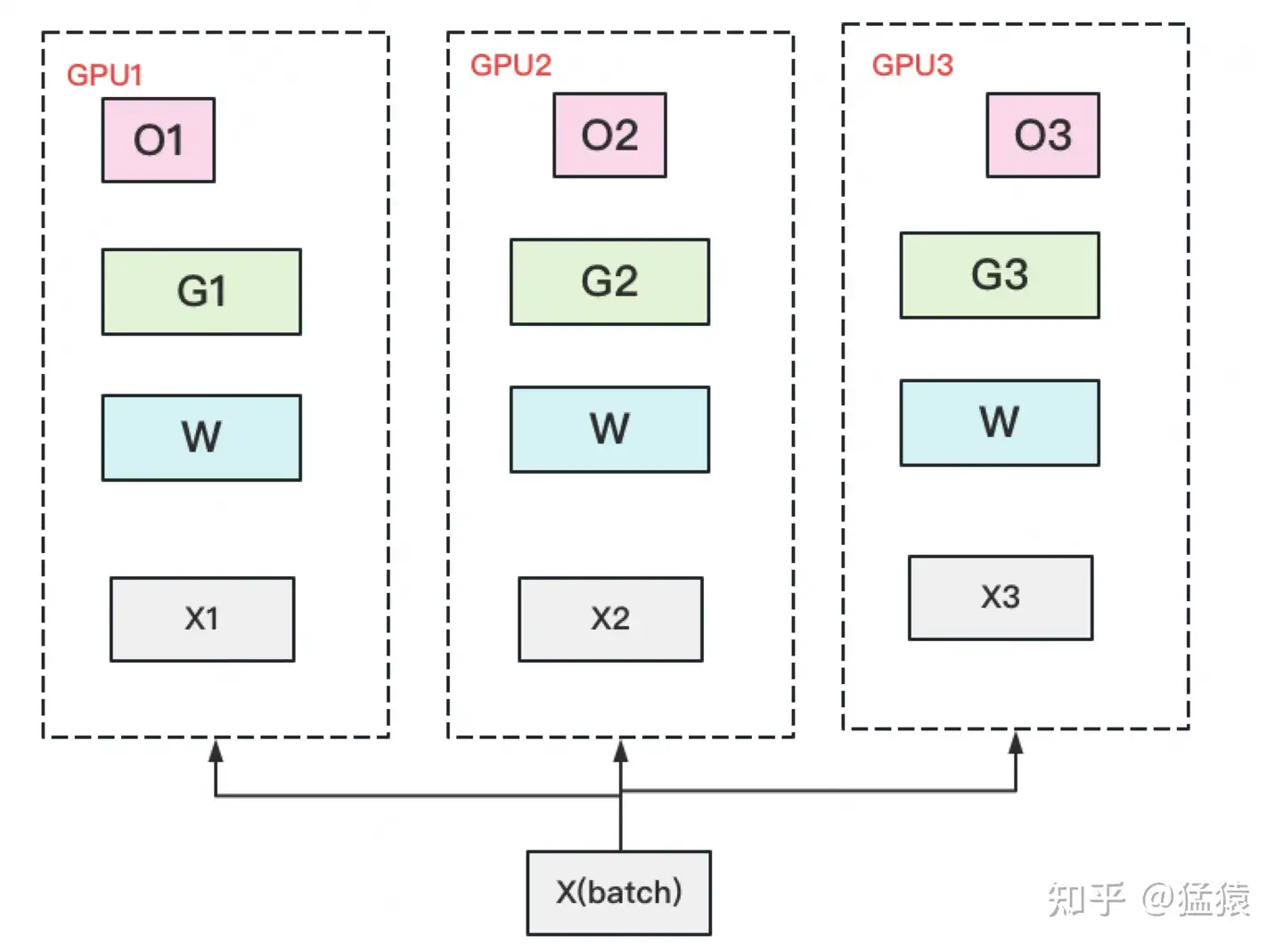
复习一下,此时W=fp16,G=fp16,O=fp32。此时,整体数据并行的流程如下:
(1)每块GPU上存一份完整的参数W。将一个batch的数据分成3份,每块GPU各吃一份,做完一轮foward和backward后,各得一份梯度。
(2)对梯度做一次AllReduce,得到完整的梯度G,产生单卡通讯量 2Φ 。为了表达简明,这里通讯量我们就不再换算成byte了,而直接根据参数量来计算。对AllReduce(reduce-scatter + all-gather)不熟悉的朋友,可以先去看上一篇文章。
(3)得到完整梯度G,就可以对W做更新。我们知道W的更新由optimizer states和梯度共同决定。由于每块GPU上只保管部分optimizer states,因此只能将相应的W(蓝色部分)进行更新。(2)和(3)可以用下图表示:

(4)此时,每块GPU上都有部分W没有完成更新(图中白色部分)。所以我们需要对W做一次All-Gather,从别的GPU上把更新好的部分W取回来。产生单卡通讯量 Φ 。
做完 𝑃𝑜𝑠 后,设GPU个数为 𝑁𝑑 ,显存和通讯量的情况如下:

假设各变量大小如表格第二列所示,那么 𝑃𝑜𝑠 在增加1.5倍单卡通讯开销的基础上,将单卡存储降低了4倍。看起来是个还不错的trade-off,那么还能做得更好吗
2.2 𝑃𝑜𝑠+𝑃𝑔 :优化状态与梯度分割
现在,更近一步,我们把梯度也拆开,每个GPU格子维护一块梯度。
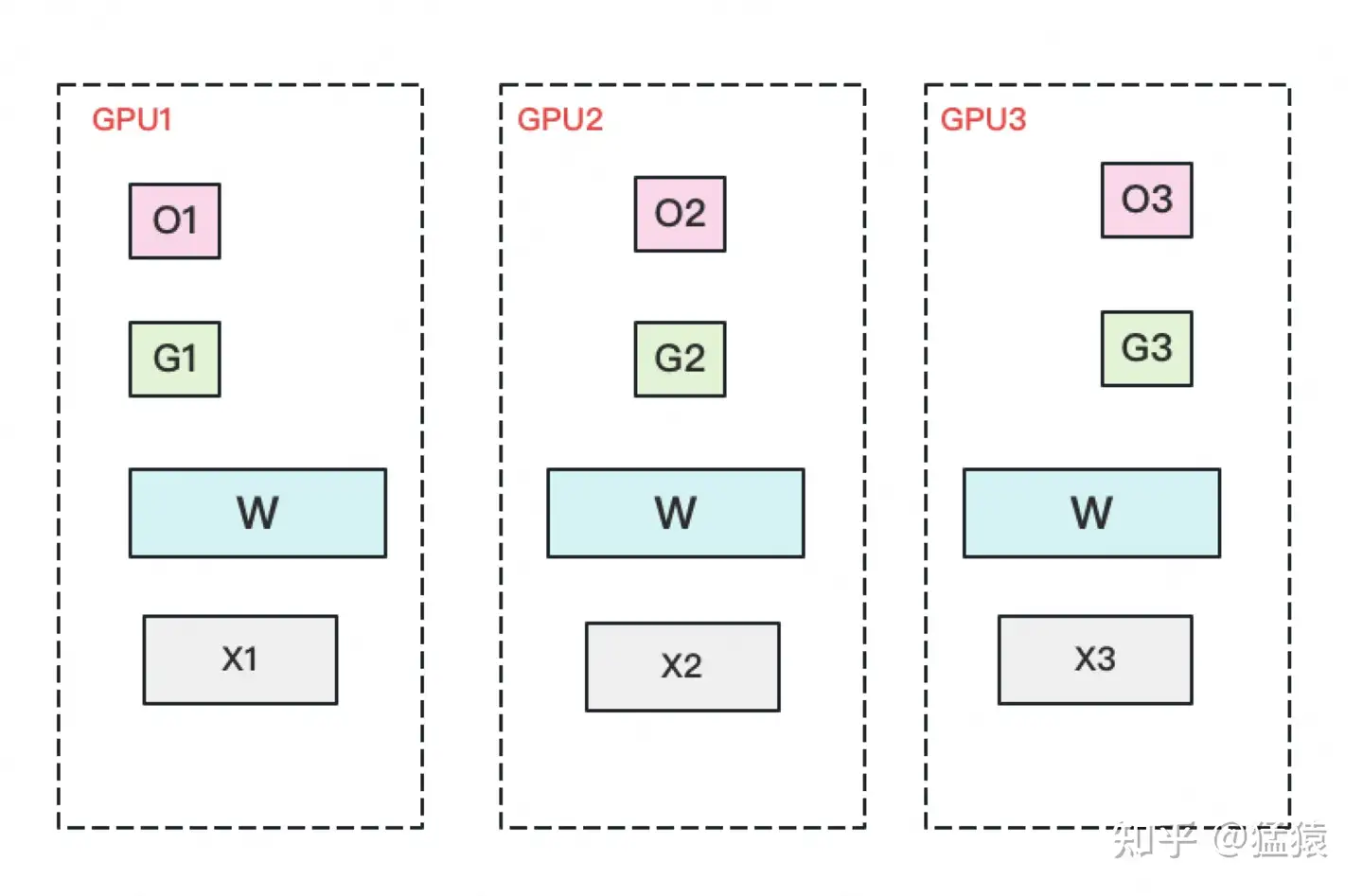
此时,数据并行的整体流程如下:
(1)每块GPU上存一份完整的参数W。将一个batch的数据分成3份,每块GPU各吃一份,做完一轮foward和backward后,算得一份完整的梯度(下图中绿色+白色)。
(2)对梯度做一次Reduce-Scatter,保证每个GPU上所维持的那块梯度是聚合梯度。例如对GPU1,它负责维护G1,因此其他的GPU只需要把G1对应位置的梯度发给GPU1做加总就可。汇总完毕后,白色块对GPU无用,可以从显存中移除。单卡通讯量 Φ 。(1)和(2)见下图:
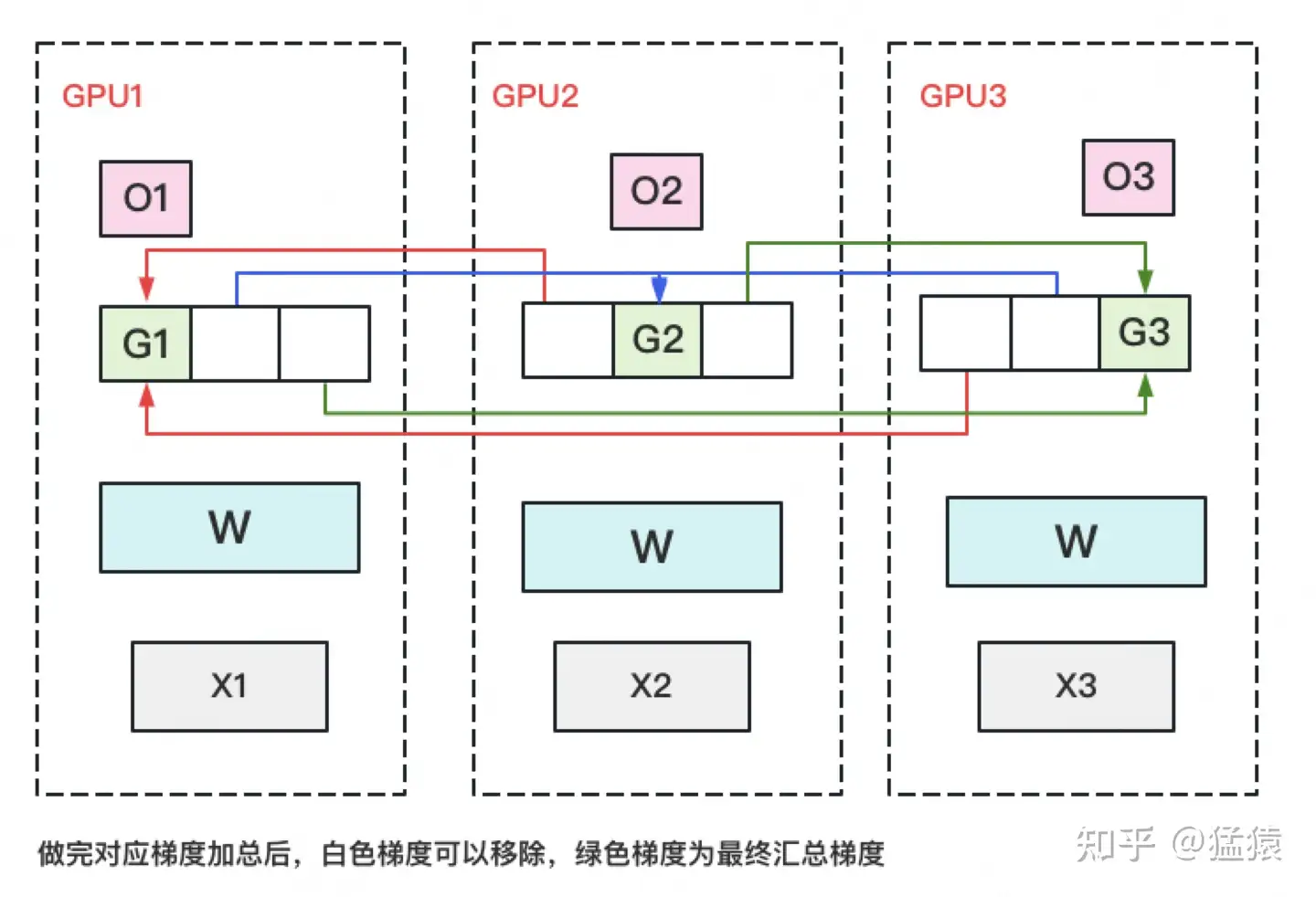
(3)每块GPU用自己对应的O和G去更新相应的W。更新完毕后,每块GPU维持了一块更新完毕的W。同理,对W做一次All-Gather,将别的GPU算好的W同步到自己这来。单卡通讯量 Φ 。
再次比对下显存和通讯量:

和朴素DP相比,存储降了8倍,单卡通讯量持平,好像更牛皮了呢!那么,还可以优化吗?
2.3 𝑃𝑜𝑠+𝑃𝑔+𝑃𝑝 :优化状态、梯度与参数分割
看到这里,也许你有点感觉了,ZeRO的思想就是:万物皆可切,万物皆可抛。所以现在,我们把参数也切开。每块GPU置维持对应的optimizer states,gradients和parameters(即W)。
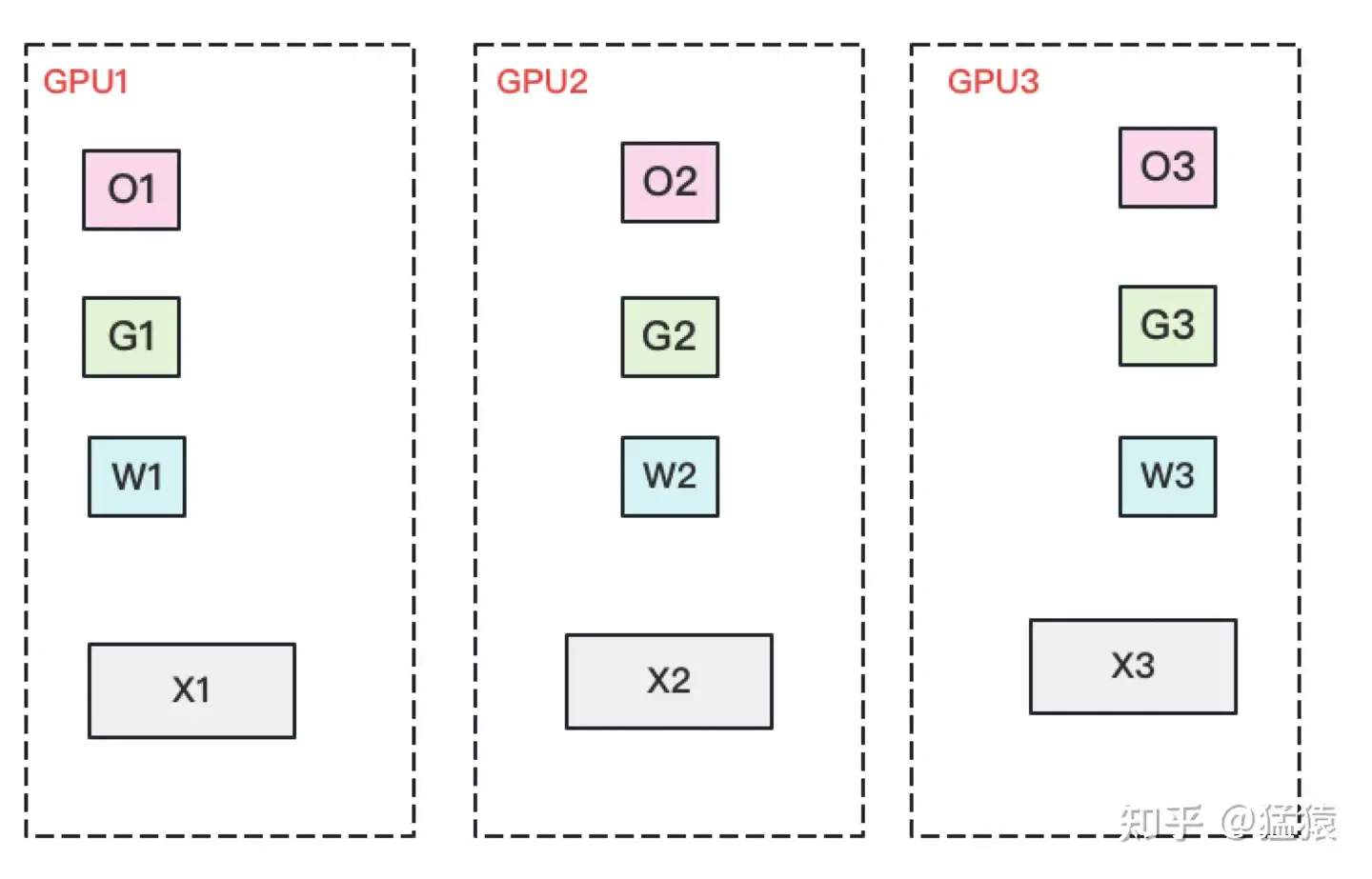
数据并行的流程如下:
(1)每块GPU上只保存部分参数W。将一个batch的数据分成3份,每块GPU各吃一份。
(2)做forward时,对W做一次All-Gather,取回分布在别的GPU上的W,得到一份完整的W,单卡通讯量 Φ 。forward做完,立刻把不是自己维护的W抛弃。
(3)做backward时,对W做一次All-Gather,取回完整的W,单卡通讯量 Φ 。backward做完,立刻把不是自己维护的W抛弃。
(4)做完backward,算得一份完整的梯度G,对G做一次Reduce-Scatter,从别的GPU上聚合自己维护的那部分梯度,单卡通讯量 Φ 。聚合操作结束后,立刻把不是自己维护的G抛弃。
(5)用自己维护的O和G,更新W。由于只维护部分W,因此无需再对W做任何AllReduce操作。
显存和通讯量如下:

到这一步,我们用1.5倍的通讯开销,换回近120倍的显存。只要梯度计算和异步更新做的好,通讯时间大部分可以被计算时间隐藏,因此这样的额外通讯开销,也是划算的。
到这里,我们可以放出原始论文中的说明图了,经过以上分析,这张说明图是不是瞬间就能看懂了。不得不吐槽下,虽然ZeRO的设计不复杂,但对应论文写得真是逻辑跳跃,晦涩难懂....
仔细一想,ZeRO其实掌握了降本增效的精髓:用完即弃,需要再补。反正我补一个和你差不多的,也不会花费很多通(找)讯(人)时间,还大大降低了我的成本。模型的每一层多算(造)几(轮)遍(子)有啥关系呢,反正在我的预算里每个人都一刻不停地干活,就行啦!
2.4 ZeRO VS 模型并行
知道模型并行的朋友,可能会想,既然ZeRO都把参数W给切了,那它应该是个模型并行呀?为什么要归到数据并行里呢?
其实ZeRO是模型并行的形式,数据并行的实质。
模型并行,是指在forward和backward的过程中,我只需要用自己维护的那块W来计算就行。即同样的输入X,每块GPU上各算模型的一部分,最后通过某些方式聚合结果。
但对ZeRO来说,它做forward和backward的时候,是需要把各GPU上维护的W聚合起来的,即本质上还是用完整的W进行计算。它是不同的输入X,完整的参数W,最终再做聚合。
因为下一篇要写模型并行Megatron-LM,因此现在这里罗列一下两者的对比。
三、ZeRO-R
说完了以上对model states的显存优化,现在来看对residual states的优化。
3.1 𝑃𝑎 : Partitioned Activation Checkpointing
前面说过,对activation的存储是灵活的。不像optimizer states,gradients和parameters对模型更新是必须的,activation只是起到加速梯度计算的作用。因此,在哪几层保存activation,保存哪些activation都是可以灵活设置的。同样,我们也可以仿照以上切割方式,每块GPU上只维护部分的activation,需要时再从别的地方聚合过来就行。需要注意的是,activation对显存的占用一般会远高于模型本身,通讯量也是巨大的,所以这块要灵活、有效地实验设计。
3.2 𝐶𝐵 : Constant Size Buffer
固定大小的内存buffer,它的目的在于:
提升带宽利用率。当GPU数量上升,GPU间的通讯次数也上升,每次的通讯量可能下降(但总通讯量不会变)。数据切片小了,就不能很好利用带宽了。所以这个buffer起到了积攒数据的作用:等数据积攒到一定大小,再进行通讯。
使得存储大小可控。在每次通讯前,积攒的存储大小是常量,是已知可控的。更方便使用者对训练中的存储消耗和通讯时间进行预估。
3.3 𝑀𝐷 : Memory Defragmentation
在前文提过,设置机制,对碎片化的存储空间进行重新整合,整出连续的存储空间。防止出现总存储足够,但连续存储不够而引起的存储请求fail
四、ZeRO-Offload与ZeRO-Infinity
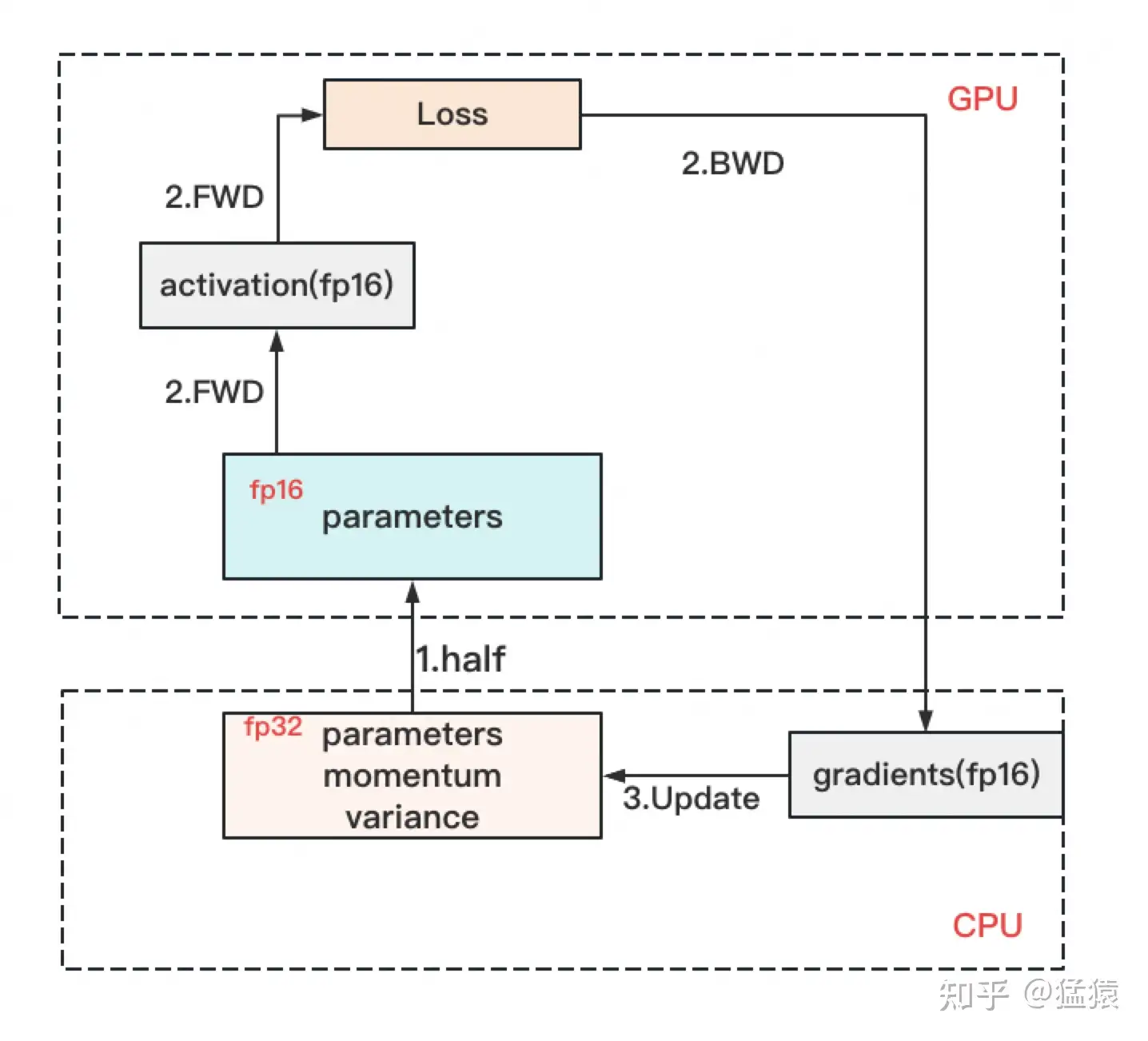
最后,简单介绍一下ZeRO-Offload。它的核心思想是:显存不够,内存来凑。如果我把要存储的大头卸载(offload)到CPU上,而把计算部分放到GPU上,这样比起跨机,是不是能既降显存,也能减少一些通讯压力呢?
ZeRO-Offload的做法是:
forward和backward计算量高,因此和它们相关的部分,例如参数W(fp16),activation,就全放入GPU。
update的部分计算量低,因此和它相关的部分,全部放入CPU中。例如W(fp32),optimizer states(fp32)和gradients(fp16)等。
具体切分如下图:
ZeRO-infinity也是同理,它们在解决的事情都是:找个除GPU之外的地方,存数据。感兴趣的朋友可以深入研究,这里就不展开了。