

一、基本概念
在我们开始讨论损失函数之前,首先需要理解什么是损失函数,以及为什么我们需要它。
1.1 什么是损失函数
损失函数,也被称为代价函数或误差函数,是一个用来估计模型预测与真实值之间差异的函数。换句话说,损失函数可以帮助我们理解模型的预测结果有多糟糕。损失函数的值越小,说明模型的预测结果与真实值越接近,模型的性能就越好。
1.2 为什么需要损失函数
在机器学习中,我们的目标是让模型能够从数据中学习并做出准确的预测。为了达到这个目标,我们需要一种方法来衡量模型的预测结果与真实值之间的差距,这就是损失函数的作用。
例如,假设我们正在训练一个用于预测房价的模型。对于每一个房子,模型都会预测一个价格,然后我们可以通过损失函数来衡量这个预测价格与房子的真实价格之间的差距。如果这个差距很小,那么我们就可以说模型的预测是准确的。反之,如果这个差距很大,那么我们就可以说模型的预测是不准确的。
总的来说,损失函数是我们优化模型、提高模型性能的关键。通过最小化损失函数,我们可以让模型学习到数据的内在规律,从而做出更准确的预测。

二、均方误差 (Mean Squared Error, MSE)
2.1 定义
均方误差(MSE)是一种常用的损失函数,用于衡量预测值与真实值之间的差异。它的数学定义如下:
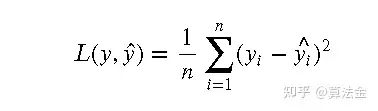
其中, 是真实值, ^ 是预测值, 是样本数量。
2.2 直观理解
均方误差可以被直观地理解为预测值和真实值之间的“距离”。每个预测值和真实值之间的差异被平方,然后求和,最后除以样本数量。这样做的好处是,差异的正负值不会互相抵消,而且差异较大的样本会有更大的权重。
2.3 适用场景
均方误差通常用于回归问题,例如预测房价、股票价格等连续值的问题。它的优点是计算简单,易于求导,非常适合用于梯度下降等优化算法。
2.4 优点和缺点
均方误差的一个主要优点是它对于异常值非常敏感。这是因为在计算均方误差时,我们会对差异进行平方,所以差异较大的样本会有更大的权重。这既可以是一个优点,也可以是一个缺点,取决于具体的应用场景。如果我们希望模型对异常值更敏感,那么均方误差是一个好的选择。但是,如果我们的数据中包含很多噪声,那么均方误差可能会导致模型过于复杂,从而过拟合。
2.5 示例
假设我们正在训练一个用于预测房价的模型。我们可以使用均方误差作为损失函数,来衡量模型的预测价格与房子的真实价格之间的差距。通过最小化均方误差,我们可以让模型学习到数据的内在规律,从而做出更准确的预测。
2.6 Python 手动实现
def mean_squared_error(y_true, y_pred):
"""计算均方误差"""
n = len(y_true)
mse = sum((y_true[i] - y_pred[i])**2 for i in range(n)) / n
return mse
# 测试
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
print(mean_squared_error(y_true, y_pred)) # 输出: 0.3752.7 实战运用(基于 PyTorch,TensorFlow)
import torch
import torch.nn as nn
# 定义损失函数
criterion = nn.MSELoss()
# 假设我们有一些预测值和真实值
y_pred = torch.tensor([2.5, 0.0, 2, 8])
y_true = torch.tensor([3, -0.5, 2, 7])
# 计算损失
loss = criterion(y_pred, y_true)
print(loss.item())
# ---
import tensorflow as tf
# 假设我们有一些预测值和真实值
y_pred = tf.constant([2.5, 0.0, 2, 8])
y_true = tf.constant([3, -0.5, 2, 7])
# 计算损失
loss = tf.keras.losses.MSE(y_true, y_pred)
print(tf.reduce_mean(loss).numpy())
三、平均绝对误差
(Mean Absolute Error, MAE)
3.1 定义
平均绝对误差(MAE)是另一种常用的损失函数,用于衡量预测值与真实值之间的差异。它的数学定义如下:
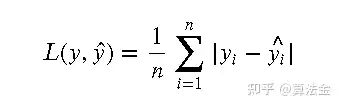
其中, 是真实值, ^^ 是预测值, 是样本数量。
3.2 直观理解
平均绝对误差可以被直观地理解为预测值和真实值之间的“距离”。不同于均方误差,它不会对差异进行平方,因此不会过分强调较大的差异。这使得它对异常值不那么敏感。
3.3 适用场景
平均绝对误差通常用于回归问题,尤其是当我们希望模型对异常值不那么敏感时。它的优点是计算简单,易于理解。
3.4 优点和缺点
平均绝对误差的一个主要优点是它对于异常值不那么敏感。这是因为在计算平均绝对误差时,我们不会对差异进行平方,所以差异较大的样本不会有过大的权重。这既可以是一个优点,也可以是一个缺点,取决于具体的应用场景。如果我们的数据中包含很多噪声,那么平均绝对误差可能是一个更好的选择。
3.5 示例
假设我们正在训练一个用于预测房价的模型。我们可以使用平均绝对误差作为损失函数,来衡量模型的预测价格与房子的真实价格之间的差距。通过最小化平均绝对误差,我们可以让模型学习到数据的内在规律,从而做出更准确的预测。
3.6 Python 手动实现
以下是一个使用Python实现平均绝对误差(MAE)的简单示例:
def mean_absolute_error(y_true, y_pred):
"""计算平均绝对误差"""
n = len(y_true)
mae = sum(abs(y_true[i] - y_pred[i]) for i in range(n)) / n
return mae
# 测试
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
print(mean_absolute_error(y_true, y_pred)) # 输出: 0.53.7 实战运用(基于 PyTorch,TensorFlow)
import torch
import torch.nn as nn
# 定义损失函数
criterion = nn.L1Loss()
# 假设我们有一些预测值和真实值
y_pred = torch.tensor([2.5, 0.0, 2, 8])
y_true = torch.tensor([3, -0.5, 2, 7])
# 计算损失
loss = criterion(y_pred, y_true)
print(loss.item())
# ---
import tensorflow as tf
# 假设我们有一些预测值和真实值
y_pred = tf.constant([2.5, 0.0, 2, 8])
y_true = tf.constant([3, -0.5, 2, 7])
# 计算损失
loss = tf.keras.losses.MAE(y_true, y_pred)
print(tf.reduce_mean(loss).numpy())
四、对数损失 (Log Loss)
4.1 定义
对数损失(Log Loss)是一种常用的损失函数,主要用于衡量分类模型的性能。它的数学定义如下:
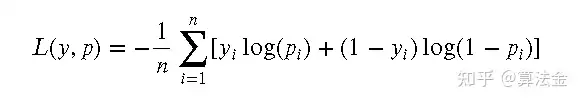
其中, 是真实标签, 是预测为正类的概率, 是样本数量。
4.2 直观理解
对数损失可以被直观地理解为预测概率与真实标签之间的“距离”。如果预测的概率完全准确(即,对于真实标签为1的样本,预测概率也为1;对于真实标签为0的样本,预测概率也为0),那么对数损失为0。反之,如果预测的概率与真实标签完全不符,那么对数损失将会无限大。
4.3 适用场景
对数损失通常用于二分类或者多分类问题,因为它可以很好地处理概率输出。对于二分类问题,我们通常使用上面的定义。对于多分类问题,我们可以使用交叉熵损失,它是对数损失的一个泛化。
4.4 优点和缺点
对数损失的一个主要优点是它可以直接衡量预测概率的准确性,而不仅仅是预测标签的准确性。这使得它在需要考虑不确定性的问题中非常有用。然而,对数损失的一个缺点是它对于预测概率的小变化非常敏感。例如,改变一个预测概率从0.01到0.02,和改变另一个预测概率从0.99到1.0,对于对数损失的影响是一样的,尽管后者的预测已经非常接近真实标签。
4.5 示例
假设我们正在训练一个用于预测猫和狗的图片的模型。我们可以使用对数损失作为损失函数,来衡量模型的预测概率与真实标签之间的差距。通过最小化对数损失,我们可以让模型学习到数据的内在规律,从而做出更准确的预测。
4.6 Python 手动实现
以下是一个使用Python实现对数损失(Log Loss)的简单示例:
import numpy as np
def log_loss(y_true, y_pred):
"""计算对数损失"""
epsilon = 1e-15 # 避免对数运算错误
y_pred = np.maximum(np.minimum(y_pred, 1 - epsilon), epsilon)
ll = -np.mean(y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred))
return ll
# 测试
y_true = np.array([0, 0, 1, 1])
y_pred = np.array([0.1, 0.2, 0.7, 0.9])
print(log_loss(y_true, y_pred)) # 输出: 0.19763488164214874.7 实战运用(基于 PyTorch,TensorFlow)
import torch
import torch.nn as nn
# 定义损失函数
criterion = nn.BCELoss()
# 假设我们有一些预测值和真实值
y_pred = torch.tensor([0.1, 0.2, 0.7, 0.9])
y_true = torch.tensor([0, 0, 1, 1], dtype=torch.float32)
# 计算损失
loss = criterion(y_pred, y_true)
print(loss.item())
# ---
import tensorflow as tf
# 假设我们有一些预测值和真实值
y_pred = tf.constant([0.1, 0.2, 0.7, 0.9])
y_true = tf.constant([0, 0, 1, 1])
# 计算损失
loss = tf.keras.losses.BinaryCrossentropy()(y_true, y_pred)
print(tf.reduce_mean(loss).numpy())
五、交叉熵损失 (Cross Entropy Loss)
5.1 定义
交叉熵损失(Cross Entropy Loss)是一种常用的损失函数,主要用于衡量分类模型的性能。它的数学定义如下:

其中, 是第 个样本的真实标签在第 类的概率, 是模型预测第 个样本在第 类的概率, 是样本数量, 是类别数量。
5.2 直观理解
交叉熵损失可以被直观地理解为预测概率分布与真实概率分布之间的“距离”。如果预测的概率分布完全准确(即,与真实的概率分布完全一致),那么交叉熵损失为0。反之,如果预测的概率分布与真实的概率分布完全不符,那么交叉熵损失将会无限大。
5.3 适用场景
交叉熵损失通常用于多分类问题,因为它可以很好地处理概率输出。对于二分类问题,我们可以使用对数损失,它是交叉熵损失的一个特例。
5.4 优点和缺点
交叉熵损失的一个主要优点是它可以直接衡量预测概率分布的准确性,而不仅仅是预测标签的准确性。这使得它在需要考虑不确定性的问题中非常有用。然而,交叉熵损失的一个缺点是它对于预测概率的小变化非常敏感。例如,改变一个预测概率从0.01到0.02,和改变另一个预测概率从0.99到1.0,对于交叉熵损失的影响是一样的,尽管后者的预测已经非常接近真实标签。
5.5 示例
假设我们正在训练一个用于识别猫、狗和鸟的图片的模型。我们可以使用交叉熵损失作为损失函数,来衡量模型的预测概率分布与真实标签的概率分布之间的差距。通过最小化交叉熵损失,我们可以让模型学习到数据的内在规律,从而做出更准确的预测。
5.6 Python 手动实现
以下是一个使用Python实现交叉熵损失(Cross Entropy Loss)的简单示例:
import numpy as np
def cross_entropy_loss(y_true, y_pred):
"""计算交叉熵损失"""
epsilon = 1e-15 # 避免对数运算错误
y_pred = np.maximum(np.minimum(y_pred, 1 - epsilon), epsilon)
ce = -np.mean(y_true * np.log(y_pred))
return ce
# 测试
y_true = np.array([[1, 0, 0], [0, 1, 0], [0, 0, 1]])
y_pred = np.array([[0.7, 0.2, 0.1], [0.1, 0.6, 0.3], [0.2, 0.2, 0.6]])
print(cross_entropy_loss(y_true, y_pred)) # 输出: 0.1531473546078571
六、Hinge Loss
6.1 定义
Hinge损失是一种常用于支持向量机(SVM)和一些类型的感知器算法的损失函数。它的数学定义如下:
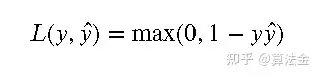
其中, 是真实标签, ̂ 是预测值。
6.2 直观理解
Hinge损失可以被直观地理解为模型预测正确时的“余量”。如果模型的预测值与真实标签的乘积大于1,那么损失为0;否则,损失为 1− ̂ 。这意味着,即使模型的预测是正确的,只要它的置信度不够(即, ̂ <1),就会产生一定的损失。
6.3 适用场景
Hinge损失通常用于二分类问题,尤其是支持向量机(SVM)和一些类型的感知器算法。它的优点是可以产生一个最大间隔分类器,即尽可能地远离决策边界。
6.4 优点和缺点
Hinge损失的一个主要优点是它对于正确分类的样本产生的损失较小,这使得它在处理大规模且高维度的数据集时非常有效。然而,Hinge损失的一个缺点是它不是可微的,这使得它不能直接用于需要损失函数可微的优化算法,如梯度下降。
6.5 示例
假设我们正在训练一个用于区分猫和狗的图片的模型。我们可以使用Hinge损失作为损失函数,来衡量模型的预测值与真实标签之间的差距。通过最小化Hinge损失,我们可以让模型学习到数据的内在规律,从而做出更准确的预测。
6.6 Python 手动实现
以下是一个使用Python实现Hinge损失(Hinge Loss)的简单示例:
import numpy as np
def hinge_loss(y_true, y_pred):
"""计算Hinge损失"""
n = len(y_true)
hl = np.mean(np.maximum(0, 1 - y_true * y_pred))
return hl
# 测试
y_true = np.array([1, -1, 1, -1])
y_pred = np.array([0.8, -0.7, 0.9, -0.8])
print(hinge_loss(y_true, y_pred)) # 输出: 0.19999999999999998
七、Huber损失 (Huber Loss)
7.1 定义
Huber损失是一种常用的损失函数,主要用于回归问题中。它的数学定义如下:
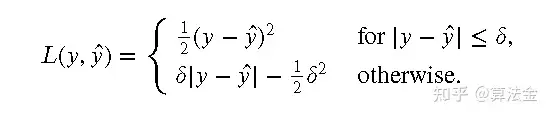
其中, 是真实值, ̂ 是预测值, 是一个常数。
7.2 直观理解
Huber损失可以被直观地理解为均方误差和平均绝对误差的结合。当预测值与真实值之间的差异较小(小于 )时,Huber损失就变成了均方误差;而当差异较大时,它就变成了平均绝对误差。这使得Huber损失在处理有噪声的数据时比均方误差更稳健,因为它对于异常值不那么敏感。
7.3 适用场景
Huber损失通常用于回归问题,尤其是当我们的数据中存在一些噪声或者异常值时。它的优点是可以在保持对数据中的正常值敏感的同时,对异常值具有鲁棒性。
7.4 优点和缺点
Huber损失的一个主要优点是它对于异常值具有鲁棒性,这使得它在处理有噪声的数据时非常有效。然而,Huber损失的一个缺点是它需要选择一个合适的 值,这需要根据具体的问题和数据来决定。
7.5 示例
假设我们正在训练一个用于预测房价的模型,但是我们的数据中存在一些异常值。我们可以使用Huber损失作为损失函数,来衡量模型的预测价格与房子的真实价格之间的差距。通过最小化Huber损失,我们可以让模型学习到数据的内在规律,从而做出更准确的预测。
7.6 Python 手动实现
以下是一个使用Python实现Huber损失(Huber Loss)的简单示例:
import numpy as np
def huber_loss(y_true, y_pred, delta=1.0):
"""计算Huber损失"""
error = y_true - y_pred
abs_error = np.abs(error)
squared_loss = 0.5 * np.square(error)
absolute_loss = delta * (abs_error - 0.5 * delta)
return np.where(abs_error <= delta, squared_loss, absolute_loss)
# 测试
y_true = np.array([3, -0.5, 2, 7])
y_pred = np.array([2.5, 0.0, 2, 8])
print(huber_loss(y_true, y_pred)) # 输出: [0.125 0.125 0. 0.5 ]
八、KL 散度损失
(Kullback-Leibler Divergence Loss, KLDivLoss)
8.1 定义
KL散度损失,也被称为相对熵,是一种衡量两个概率分布之间差异的损失函数。它的数学定义如下:
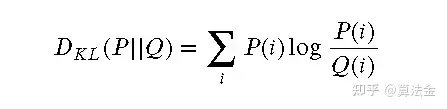
其中, ( ) 是真实的概率分布, ( ) 是预测的概率分布。
8.2 直观理解
KL散度损失可以被直观地理解为真实概率分布和预测概率分布之间的“距离”。如果预测的概率分布完全准确(即,与真实的概率分布完全一致),那么KL散度损失为0。反之,如果预测的概率分布与真实的概率分布完全不符,那么KL散度损失将会无限大。
8.3 适用场景
KL散度损失通常用于概率分布的预测问题,例如主题模型、自编码器等。它的优点是可以直接衡量预测概率分布的准确性,而不仅仅是预测标签的准确性。
8.4 优点和缺点
KL散度损失的一个主要优点是它可以直接衡量预测概率分布的准确性,这使得它在需要考虑不确定性的问题中非常有用。然而,KL散度损失的一个缺点是它对于预测概率的小变化非常敏感。例如,改变一个预测概率从0.01到0.02,和改变另一个预测概率从0.99到1.0,对于KL散度损失的影响是一样的,尽管后者的预测已经非常接近真实标签。
8.5 示例
假设我们正在训练一个用于预测文本主题的模型。我们可以使用KL散度损失作为损失函数,来衡量模型的预测主题分布与真实主题分布之间的差距。通过最小化KL散度损失,我们可以让模型学习到数据的内在规律,从而做出更准确的预测。
8.6 Python 手动实现
以下是一个使用Python实现KL散度损失(KLDivLoss)的简单示例:
import numpy as np
def kl_divergence(p, q):
"""计算KL散度损失"""
return np.sum(p * np.log(p / q))
# 测试
p = np.array([0.36, 0.48, 0.16])
q = np.array([0.333, 0.333, 0.333])
print(kl_divergence(p, q)) # 输出: 0.08630010165195404[ 抱个拳,总个结 ]
损失函数的选择
选择合适的损失函数是机器学习中非常重要的一步。不同的问题可能需要使用不同的损失函数。例如,对于回归问题,我们通常会选择均方误差(MSE)或者平均绝对误差(MAE);对于分类问题,我们可能会选择对数损失(Log Loss)或者交叉熵损失(Cross Entropy Loss)。
选择损失函数时,我们需要考虑以下几个因素:
问题类型:不同类型的问题(如回归、分类、排序等)可能需要使用不同的损失函数。
数据分布:如果数据中存在很多异常值,那么我们可能需要选择对异常值不敏感的损失函数,如Huber损失。
模型复杂性:某些损失函数可能会导致模型过于复杂,从而导致过拟合。在这种情况下,我们可能需要选择其他的损失函数。
此外,我们还可以根据具体的问题和需求来自定义损失函数。自定义损失函数可以让我们更好地捕捉到问题的特性,从而提高模型的性能。
损失函数在优化中的作用
损失函数在模型训练中起着至关重要的作用。通过最小化损失函数,我们可以让模型学习到数据的内在规律,从而做出更准确的预测。
在优化过程中,我们通常会使用一种叫做梯度下降的方法来最小化损失函数。梯度下降的基本思想是,如果我们要找到一个函数的最小值,那么最好的方式就是沿着该函数的负梯度方向进行搜索。
具体来说,我们首先会随机初始化模型的参数,然后计算损失函数关于这些参数的梯度。然后,我们会按照梯度的反方向更新参数,以此来减小损失函数的值。我们会重复这个过程,直到损失函数的值不再显著减小,或者达到预设的迭代次数。
通过这种方式,我们可以找到一组参数,使得损失函数达到最小值,从而得到一个性能较好的模型。
总的来说,损失函数在模型训练中起着至关重要的作用。通过选择合适的损失函数,并使用有效的优化算法,我们可以训练出性能优良的模型。